
In der heutigen, schnelllebigen digitalen Welt ist der Zugang zur richtigen Information zur richtigen Zeit ein entscheidender Wettbewerbsvorteil. Genau hier kommen große Sprachmodelle (LLMs) ins Spiel. Diese fortschrittlichen KI-Systeme können menschenähnlichen Text verstehen und generieren, was sie für Nutzer:innen und Anbieter von Dokumentenmanagement-Systemen äußerst relevant macht. Der Zugriff auf unternehmenseigene Inhalte, die auf dieser Technologie basieren, ist jedoch nicht ganz so einfach. In diesem Blogartikel schauen wir uns die grundlegende Technologie an, die es Dir ermöglicht, große Mengen an Dokumenten sicher und effizient mit modernster KI-Technologie zu durchforsten und erklären, was Retrieval Augmented Generation damit zu tun hat. Dabei werfen wir einen Blick unter die Motorhaube der neuesten Innovationen von d.velop im Bereich des modernen Dokumentenmanagements. Aber bevor wir tiefer einsteigen, betrachten wir ein Beispiel aus dem Arbeitsalltag, das Dir sicher vertraut ist:
Stell Dir vor, Du arbeitest an einem wichtigen Projekt und musst schnell spezifische Informationen in einem umfangreichen Dokumentenarchiv Deines Unternehmens finden. Traditionell könnte dies bedeuten, eine manuelle Suchanfrage zu formulieren, zahllose Dateien zu öffnen, sie durchzusehen, Absätze genau zu lesen und gleichzeitig Deine Erkenntnisse zu notieren. Das kann mühsam und zeitaufwendig sein. Doch was, wenn es einen intelligenteren Weg gäbe, genau das zu bekommen, was Du brauchst – und das sofort?
Was versteht man unter Retrieval Augmented Generation (RAG)?
Retrieval Augmented Generation (RAG) ist eine wegweisende Technologie, die die Stärken großer Sprachmodelle mit intelligenten Suchmechanismen kombiniert und Dir gezielte Antworten direkt aus Deinen eigenen Daten liefert. Stell Dir RAG wie einen wissenden Assistenten vor, der Deine Fragen nicht nur versteht, sondern auch genau weiß, wo in Deinem Dokumentenmanagement-System die passenden Antworten zu finden sind.
Lies weiter, um herauszufinden, wie Retrieval Augmented Generation Dein Unternehmen unterstützen kann, indem sie wichtige Informationen mühelos zugänglich macht – genau dann, wenn Du sie brauchst! Also, lass uns gemeinsam Deine eigene RAG-Pipeline aufbauen.
Große Sprachmodelle – Autovervollständigung auf Steroiden
Um einen virtuellen Assistenten zu entwickeln, der Deine Fragen beantworten kann, ist es wichtig, das Grundprinzip hinter einem großen Sprachmodell zu verstehen. Stell Dir vor, Du tippst auf Deinem Smartphone eine Nachricht ein. Sobald Du mit „Taten sagen mehr als …“ anfängst, schlägt die Autovervollständigungsfunktion „Worte“ als Fortsetzung des Sprichworts vor. Das ist ein einfaches Beispiel dafür, wie ein Sprachmodell funktioniert – es sagt voraus und generiert Text, basierend auf Mustern, die es in riesigen Datenmengen gelernt hat. Im Grunde ist es eine hochentwickelte Version der Autovervollständigung auf Deinem Handy, die jedoch viel komplexere Aufgaben bewältigen kann.
Wenn ein LLM längere Texte generieren soll, wiederholt es diesen Vorgang einfach. Bei der Eingabe “When shall we three meet again?“ sagt das Modell zunächst „In“ voraus. Anschließend wird diese Ausgabe zum Ausgangstext hinzugefügt, wodurch der Satz „When shall we three meet again? In…“ entsteht. Diese Iteration führt schließlich zur Eröffnungsszene von Shakespeares Macbeth: “When shall we three meet again? In thunder, lightning, or in rain?”.
LLMs sind also äußerst leistungsfähig darin, plausiblen Text auf Basis eines Prompts zu generieren. Und weil sie mit einem Großteil des im Internet bekannten Wissens trainiert wurden, sind sie ausgezeichnet darin, auf nahezu jede Frage Antworten zu liefern. Manchmal sind sie jedoch zu gut. Sie neigen dazu, Dinge zu erfinden. Dies wird als „Halluzination“ bezeichnet. Das ist problematisch, da dies nicht immer sofort erkennbar ist. Außerdem hat ein LLM keinen Zugriff auf die unternehmenseigenen Daten – und das aus gutem Grund.
Wie kannst Du Deine eigenen Inhalte integrieren?
Hier kommt Retrieval Augmented Generation (RAG) ins Spiel. RAG kombiniert die Stärken eines vortrainierten Large Language Model (LLM) mit fortschrittlichen Retrieval-Mechanismen. Du kannst Dir das System wie einen unglaublich versierten Assistenten vorstellen, der Deine Fragen versteht und genau weiß, wo die relevantesten Informationen in Deinem d.velop-Dokumenten-Repository zu finden sind. Die folgende Abbildung zeigt Dir eine schematische Übersicht über das Konzept, das wir umsetzen wollen.
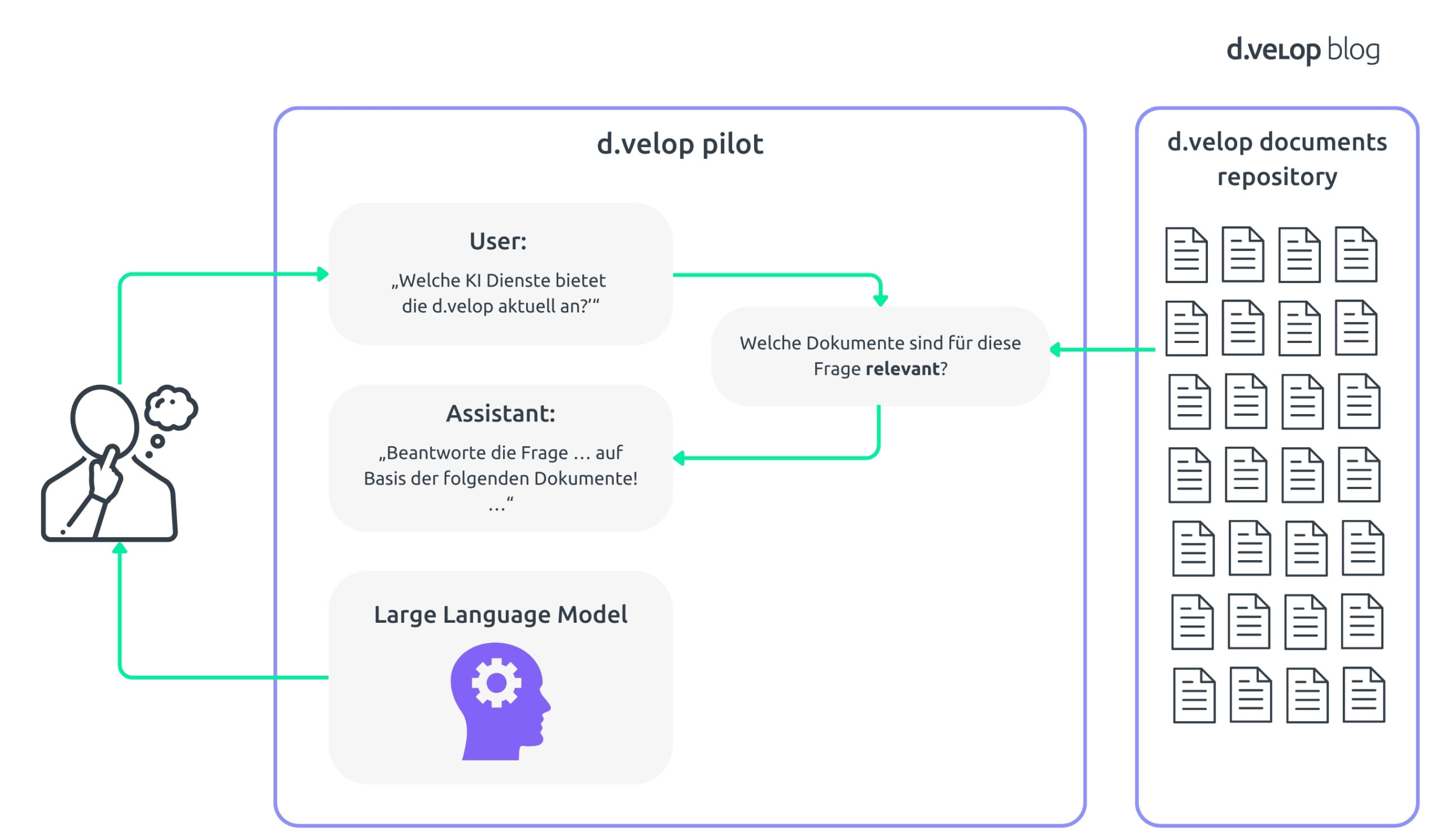
So funktioniert es: Wenn Du eine Frage stellst oder eine Suchanfrage startest, durchsucht das System zuerst die Dokumente Deines Unternehmens, um relevante Informationen zu finden. Die KI verwendet diese Daten dann, um genaue und kontextuell passende Antworten zu generieren. Dadurch erhältst Du präzise Antworten, die genau auf Deine Bedürfnisse zugeschnitten sind.
Im Wesentlichen verändert Retrieval Augmented Generation die Art und Weise, wie wir mit digitalen Inhalten interagieren, und macht sie zugänglicher und anwendbarer. Egal, ob Du Berichte verfasst, Präsentationen vorbereitest oder strategische Entscheidungen triffst – RAG stellt sicher, dass Du zeitnah die relevanten Informationen zur Verfügung hast und so Deine Digitalisierungsprojekte effizienter und wirkungsvoller gestalten kannst.
Wie werden „relevante Inhalte“ erkannt?
Mit einer Grundstruktur im System geht es nun darum, effizient zu bestimmen, welche Inhalte bei einer bestimmten Frage oder Anfrage relevant sind. Hier wird es spannend: Statt das gesamte Dokumentenarchiv Deines Unternehmens zu durchsuchen – ein teurer und zeitaufwendiger Prozess, der zudem das Risiko birgt, dass Deine geschützten Inhalte an Dritte gelangen könnten – nutzt RAG eine clevere Methode.
Einfach gesagt verwendet RAG fortschrittliche mathematische Techniken, um Sprache zu verstehen und zu verarbeiten. Im Kern stehen sogenannte Word Embeddings – numerische Darstellungen von Wörtern, die deren Bedeutung im jeweiligen Kontext erfassen. Lass uns das Schritt für Schritt erklären.
Da Computer hervorragend mit Zahlen umgehen können, aber nicht so gut mit Sprache, ist es unser erstes Ziel, „Worte in Zahlen zu übersetzen“. Optimalerweise spiegelt diese Transformation die Bedeutung der Wörter wider. Die Details sind mathematisch komplex, aber wir stellen hier eine grundlegende Intuition vor – das Schlüsselkonzept der „Word Embeddings“.
Was sind Word Embeddings?
Erinnere Dich an die Schulzeit, als Du Vektoren kennengelernt hast – diese kleinen Pfeile, die in verschiedene Richtungen zeigen. Im Bereich Natural Language Processing (NLP) verwenden wir solche Vektoren, um die Bedeutung von Wörtern darzustellen. Ein Sprachmodell, also ein speziell trainiertes neuronales Netzwerk, wird darauf trainiert, ein Wort oder eine Phrase auf einen hochdimensionalen Vektor abzubilden. Dieses Modell nennen wir Embedding Model. Die folgende Grafik veranschaulicht dieses Prinzip:
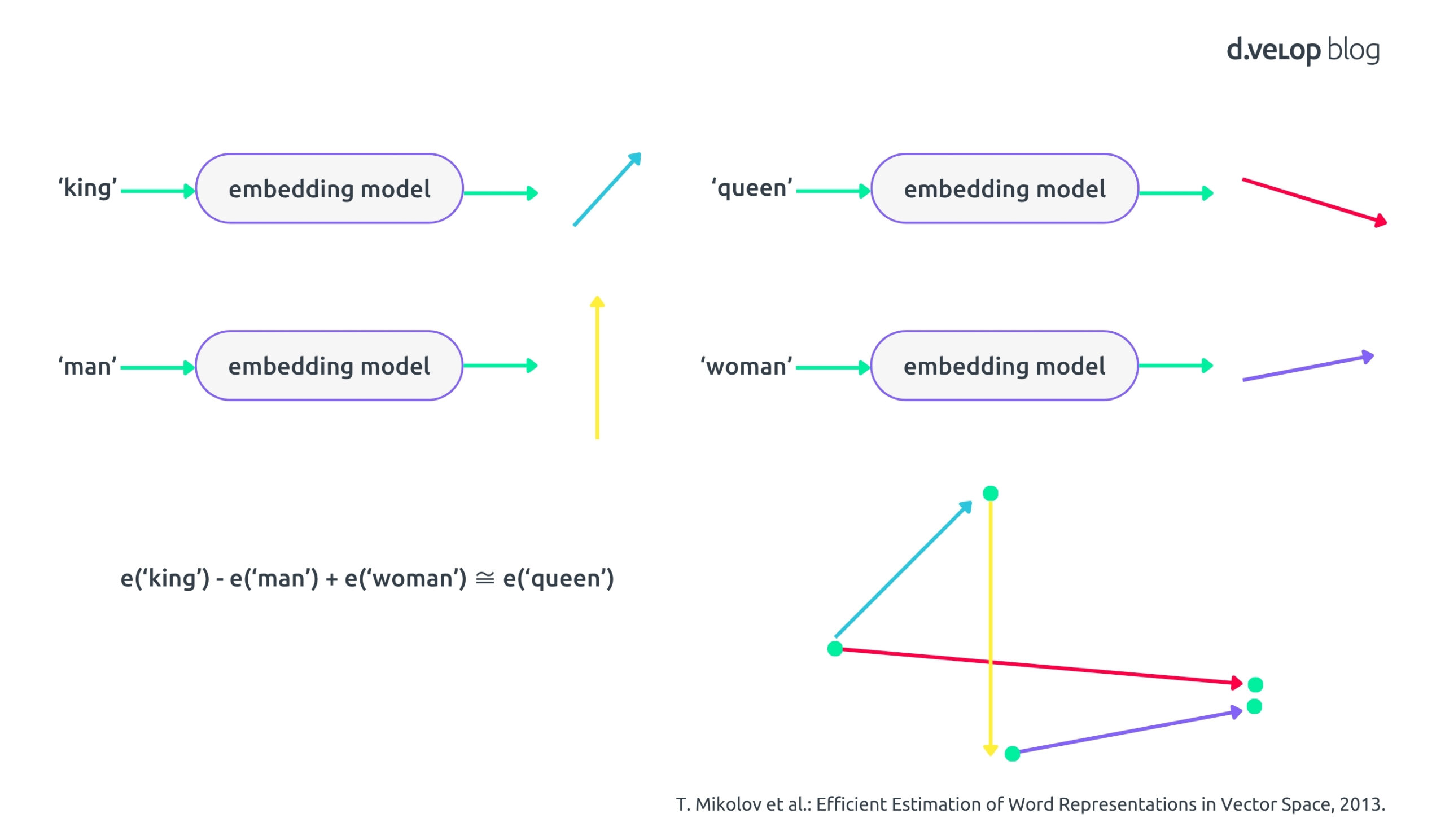
Um ein Beispiel zu geben: Wenn Du den Embedding-Vektor für „king“ (türkis) nimmst, den Vektor für „man“ (gelb) subtrahierst und den Vektor für „woman“ (lila) addierst, erhältst Du einen Vektor, der dem für „queen“ (rot) sehr ähnlich ist. Dieses klassische Beispiel zeigt, wie diese Vektoren tiefe Einblicke in die Semantik von Wörtern ermöglichen. Für eine detaillierte, theoretisch fundierte Darstellung empfehlen wir den Artikel von Mikolov et al. [T. Mikolov et al.: Efficient Estimation of Word Representations in Vector Space, 2013].
Von den Word Embeddings ist es nur ein kleiner Schritt zu Document Embeddings: Mit denselben Mechanismen können wir Vektoren berechnen, die die Bedeutung ganzer Sätze oder Dokumente erfassen. In der Praxis unterteilen wir jedes Dokument in mehrere Abschnitte und berechnen für jeden Abschnitt einen Vektor. Zur Vereinfachung verwenden wir im Folgenden den Begriff Document Embeddings, als ob jedes Dokument nur einen Vektor hätte.
Wie wird Relevanz berechnet?
Nun, da wir Word- und Document Embeddings verstehen, sehen wir uns an, wie sie uns helfen, Relevanz zu definieren. Wenn Du eine Frage stellst oder eine Suchanfrage startest, können wir diese ebenfalls als Vektor darstellen. Der Vektor spiegelt die wesentliche Bedeutung Deiner Anfrage wider. Dasselbe machen wir für jedes Dokument, und beide Vektoren – sowohl für die Anfrage als auch für die Dokumente – erfassen die „Bedeutung“, was uns ermöglicht, sie miteinander zu vergleichen. Dies geschieht mithilfe der Cosinus-Ähnlichkeit. Im Grunde entspricht die Relevanz zwischen einem Dokument und Deiner Anfrage dem Winkel zwischen den jeweiligen Embedding-Vektoren.
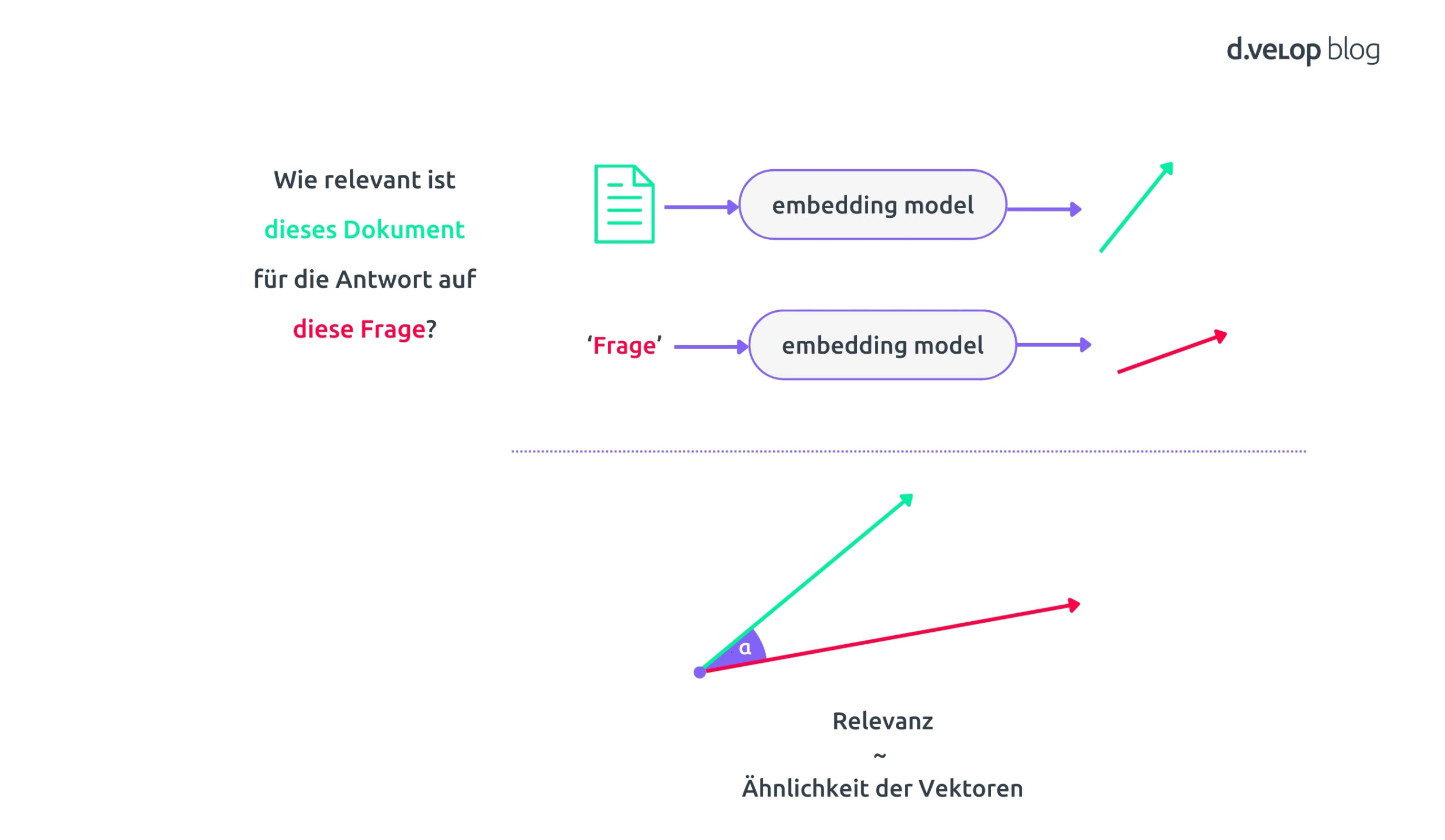
Wenn die Vektoren sehr ähnlich sind, also in dieselbe Richtung zeigen, ist das Dokument sehr relevant für Deine Anfrage. Wenn sie nicht ähnlich sind, dann ist das Dokument nicht relevant.
Effizientes Abfragen von Dokumenten
Stell Dir vor, Du hast eine riesige Bibliothek voller Dokumente – Verträge, Berichte, E-Mails und vieles mehr. Die Vektoren für alle Dokumente jedes Mal neu zu berechnen, wäre rechenintensiv und langsam.
Glücklicherweise ändern sich die Dokumente nicht ständig. Daher können wir die Vektoren der Dokumente vorab berechnen. Neue Berechnungen sind nur dann erforderlich, wenn ein neues Dokument hinzugefügt oder ein bestehendes Dokument aktualisiert wird. Die Vektoren speichern wir in einer speziellen Vektordatenbank oder einem Vektorindex, was eine schnelle (approximative) Abfrage der Vektoren ermöglicht. Die Datenbank-Engine findet dann die Vektoren, die dem Abfragevektor am ähnlichsten sind.
Dokumentenmanagement einfach erklärt
Was passiert nun, wenn Du eine Frage eingibst? Angenommen, Du suchst bestimmte Klauseln in einem Vertrag oder spezifische Details in einem Jahresbericht. So funktioniert das System:
- Anfragen-Transformation: Deine Frage wird in einen eigenen Embedding-Vektor umgewandelt.
- Datenbankabfrage: Das System verwendet diesen Vektor, um die Vektordatenbank abzufragen.
- Ergebnisermittlung: Durch effizientes Berechnen der Ähnlichkeit zwischen Abfrage- und Dokumentvektoren anhand der Cosinus-Ähnlichkeit identifiziert das System die relevantesten Abschnitte.
Um den Prozess abzurunden, werden Deine Eingabefrage und die relevanten Dokumente in eine Abfrageformulierung gepackt. Diese Abfrage nutzt die Fähigkeiten des zugrunde liegenden LLM optimal und stellt sicher, dass die Antworten auf die Dokumente gestützt werden – das minimiert das Risiko für falsche Antworten. Der gesamte Prozess wird in der folgenden schematischen Darstellung veranschaulicht.
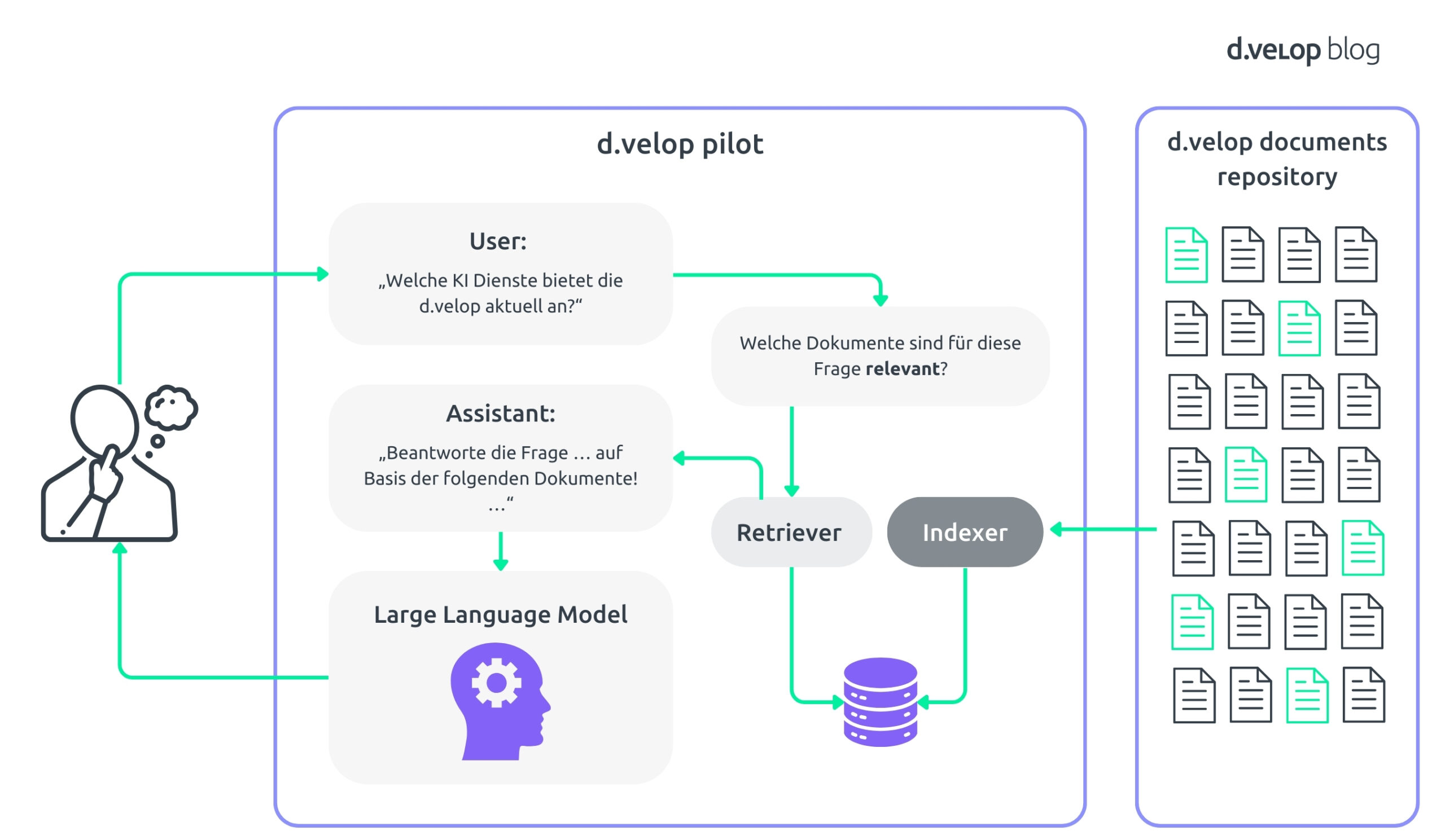
Dies ist Deine grundlegende Pipeline für Retrieval Augmented-Generation (RAG). Die Abkürzung passt perfekt: Der abschließende Generierungsprozess, der dafür sorgt, Deine Frage präzise zu beantworten, wird durch einen vorherigen Retrieval-Schritt unterstützt. So wird eine Auswahl von Dokumenten erstellt, die alle nötigen Informationen enthalten.
Umsetzung in der Produktion
Eine Standardimplementierung ist für Demos ausreichend, aber für den produktiven 24/7-Betrieb braucht es mehr. Hier spielen Sicherheit und Datenschutz eine entscheidende Rolle.
Geregelter Informationszugang
Stell Dir vor, Du arbeitest an einem sensiblen Projekt in Eurem d.velop-Dokumentenarchiv. Natürlich sollten nicht alle Zugriff auf alle Projektunterlagen haben, und die Zugriffsrechte sind oft komplex. Eine uneingeschränkte RAG-Pipeline würde jedoch jede Frage beantworten, egal wer sie stellt.
Dank der Möglichkeit, detaillierte und fein abgestufte Zugriffsrechte festzulegen, war es schon immer ein zentraler Bestandteil von d.velop documents, Informationen zu schützen. Unsere RAG-Implementierung baut auf dieser Grundlage auf, sodass bei Anfragen die KI nur Dokumente abruft, auf die Du tatsächlich Zugriff hast.
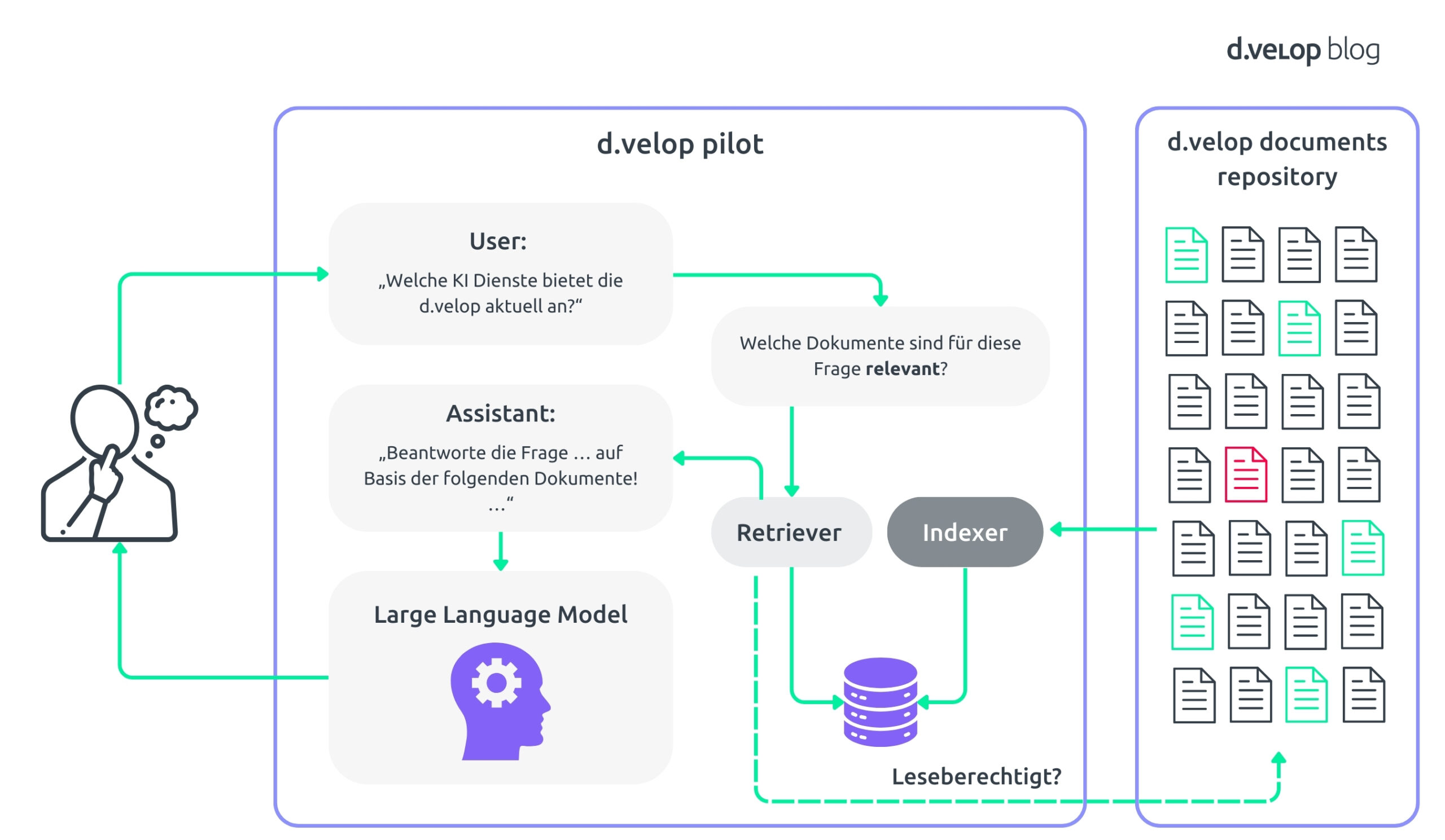
Nehmen wir an, Sarah aus dem Marketingteam stellt eine Frage zu Deinem sensiblen Projekt. Da Sarah nicht zum Projektteam gehört, hat sie keinen Zugriff auf das Projektangebot und die zugehörigen Dokumente. Die RAG-Pipeline antwortet Sarah daher allgemein und teilt mit, dass zu ihrem Thema keine Informationen gefunden wurden.
Zusammengefasst: Nur die Mitarbeitenden, die eine Berechtigung haben, sehen auch die Inhalte, die für sie bestimmt sind. So bleiben sensible Informationen geschützt und die Compliance mit Unternehmensrichtlinien ist gewährleistet.
Deine Daten bleiben Deine Daten
Per Definition sind große Sprachmodelle wirklich groß. Daher greifen wir auf externe Cloud-Angebote wie Microsoft Azure OpenAI Services, Amazon Bedrock oder Anthropic zurück, die das Modell über entsprechende APIs bereitstellen.
Das bringt die Frage auf: Wer hat Zugriff auf Deine Daten? Keine Sorge. Datenschutz ist uns ein großes Anliegen. Beim Indexieren – also beim Vorbereiten von Dokumenten für den Abruf – hast Du die volle Kontrolle, was indiziert wird und was nicht. Alles andere bleibt unberührt. Dabei werden alle Daten stets verschlüsselt, sowohl bei der Speicherung als auch während der Übertragung. Das gilt selbstverständlich auch für die Vektordatenbank.
Darüber hinaus prüfen wir jeden LLM-Anbieter gründlich auf deren Datenschutzbestimmungen. Wir verwenden nur Dienste, die explizit zusichern, Deine Daten nicht für Trainingszwecke zu verwenden. Zudem wählen wir nur Anbieter aus, die ihre Dienste innerhalb der EU hosten, um Übertragungen in Drittländer zu verhindern und somit den Anforderungen der DSGVO zu entsprechen.
Workflow-Management in der Praxis: Erlebe jetzt das d.velop process studio
Fazit
Da hast Du es: Ein funktionsfähiges RAG-System, das schnellen Datenzugriff gewährleistet und gleichzeitig Deine Datenschutz- und Sicherheitsanforderungen berücksichtigt. Nun, da das System einsatzbereit ist, gehen wir einen Schritt weiter und betrachten konkrete Beispiele:
- Rechtsabteilung: Stell Dir vor, Du bist Teil eines juristischen Teams und musst in tausenden Verträgen nach einer bestimmten Klausel suchen, die in Eurem d.velop-Dokumentenarchiv abgelegt sind. Mit RAG tippst Du einfach Deine Anfrage in natürlicher Sprache ein („Verträge mit unbegrenzter Haftungsklausel finden“), und schon erhältst Du in wenigen Augenblicken präzise Ergebnisse – ganz ohne mühsames Durchsuchen jedes Dokuments.
- Kundensupport: Wenn Du Kundenanfragen zu Produktanleitungen oder Serviceverträgen bearbeitest, hilft Dir RAG dabei, schnell relevante Abschnitte aus umfassenden Dokumentationen zu finden. So kannst Du schneller und präziser auf Kundenanfragen reagieren.
- F&E-Teams: Stell Dir vor, Du arbeitest an einem Projektvorschlag und benötigst Hintergrundinformationen zu ähnlichen Projekten aus der Vergangenheit. Mit dem RAG-fähigen Dokumentenarchiv erhältst Du relevante Dokumente aus früheren Projekten und eine prägnante Antwort, mit der Du weiterarbeiten kannst. Die Dokumente stehen Dir für eine tiefere Recherche jederzeit zur Verfügung. Für wissenschaftliche Teams, die auf Informationen aus zahlreichen Artikeln, Whitepapers und Berichten zugreifen müssen, spart RAG stundenlanges Suchen und stellt sicher, dass alle relevanten Daten verfügbar sind.
Wie Du siehst, revolutioniert generative KI und insbesondere große Sprachmodelle die Art und Weise, wie wir Wissensarbeit leisten. Diese Technologien beseitigen Informationsbarrieren. Du stellst Deine Frage in einfacher Sprache, und die Technik im Hintergrund liefert Dir präzise Antworten.
Mit dieser leistungsstarken Technologie bleibt d.velop documents führend in Sachen Innovation – gebaut auf Vertrauen und für sicheren, effizienten Informationszugang. Wir testen unsere erste RAG-Implementierung aktuell in einem geschlossenen Betaprogramm. Freu Dich auf die allgemeine Veröffentlichung im Winter! Wenn wir Dein Interesse geweckt haben, freuen wir uns auf Dein Feedback.
Vereinbare ein Gespräch mit unseren KI-Experten, erzähle uns von Deinen Informations-Herausforderungen und beginne Deine Reise zur Informationsbeschleunigung mit d.velop noch heute.