
Das automatische Erfassen und Auslesen von Rechnungen ist einer der wichtigsten Bestandteile bei der digitalen Rechnungsverarbeitung. In diesem Artikel erfährst Du am Beispiel unserer digitalen Rechnungsverarbeitungslösung d.velop invoices, welche Techniken bei der Rechnungserfassung zum Einsatz kommen, um z.B. Bestellnummern, Positionen, Beträge sowie viele weitere Daten automatisiert auszulesen.
Rechnungen erfassen und auslesen
Rechnungen können über die unterschiedlichsten Wege im Unternehmen eintreffen. Sei es nun per E-Mail, aus verschiedenen Webportalen oder ganz klassisch per Post. Alle eingehenden Rechnungen werden in eine zentrale Verarbeitungsstrecke geführt. Zunächst wird eine Optical Character Recognition (kurz: OCR; z.Dt.: Texterkennung) bei den Rechnungen durchgeführt. Hierbei werden alle auf der Bilddatei einer Rechnung vorhandenen Informationen in Text umgewandelt. Diese Daten werden im Anschluss zur Auslesekomponente geschickt.
Diverse Informationen wie z.B. die Empfangs-E-Mail-Adresse oder Informationen aus 1D- und 2D-Barcodes können direkt der Softwarekomponente zugefügt werden, welche die Daten ausliest. Auch die Daten aus rein elektronischen Rechnungsformaten (z.B. XRechnungen) können sofort als gesicherte Informationen in den Folgeprozess übergeben werden.
Bei der Analyse des Inhaltes einer Rechnung werden schließlich mehrere Erkennungsstrategien kombiniert. Als Erstes wird versucht, die ausgelesen Informationen mithilfe von Stammdaten aus der Datenbank des Unternehmens zu validieren. Diese Methode liefert sehr sichere und valide Ergebnisse. Wie wichtig gut gepflegte Stammdaten für ein Unternehmen sind, haben wir in unserem Blogartikel „Valide Stammdaten – Ein Must-Have für Unternehmen“ bereits betrachtet. Liegen keine Stammdaten vor, gibt es verschiedene generische Methoden zur Erkennung aller relevanten Informationen.
Rechnungserfassung in 5 Schritten
Im Folgenden wird beispielhaft eine exemplarische Reihenfolge von Ereignissen innerhalb der Auslesekomponente näher betrachtet. Es wird hier davon ausgegangen, dass valide Stammdaten vorliegen. Die nachfolgend beschriebenen Schritte der Rechnungserfassung sind für Endanwender:innen nicht sichtbar.
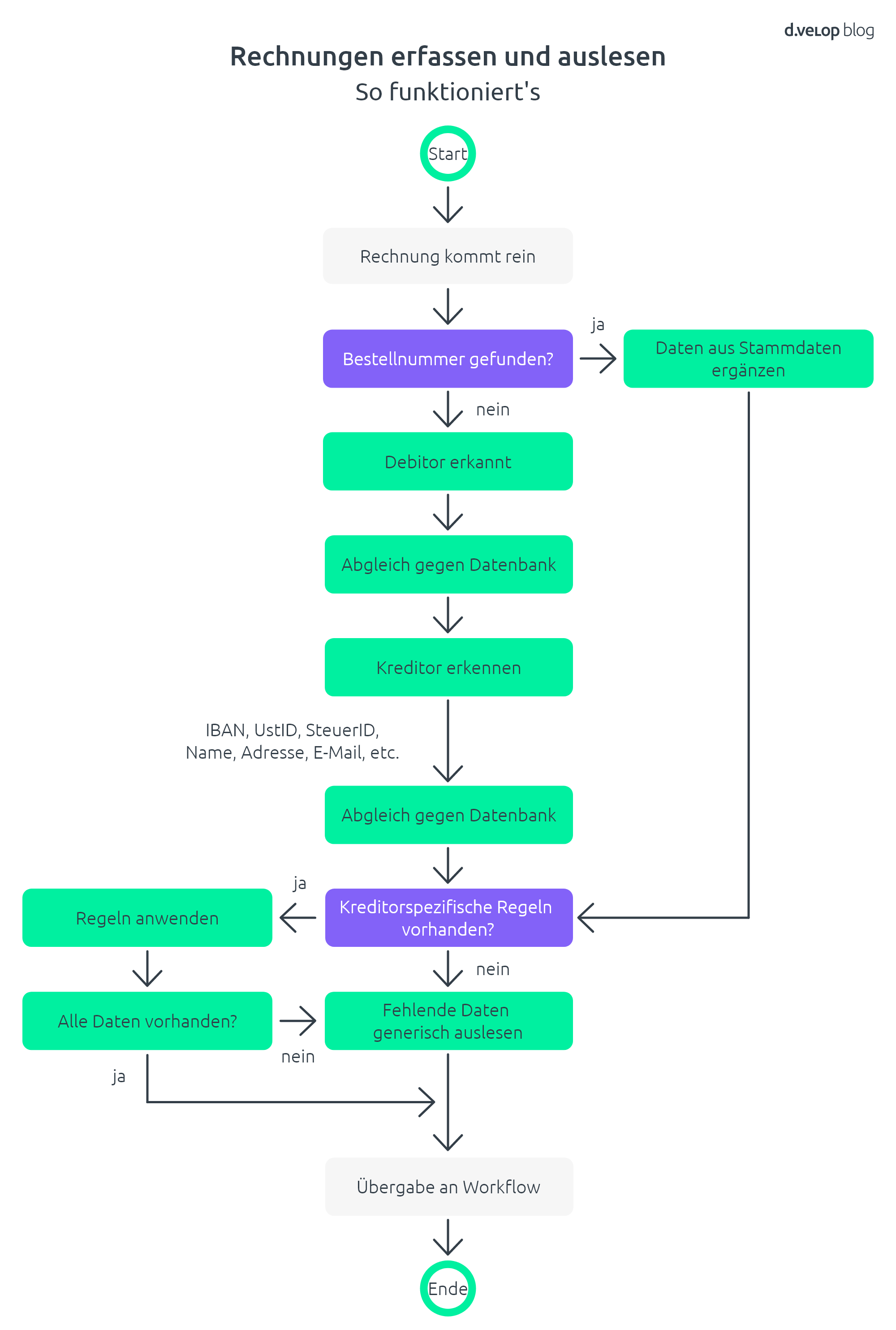
1) Erkennung der Bestellnummer
Bei Rechnungen mit Bestellbezug befinden sich bereits viele nützliche Informationen in der Datenbank des Unternehmens. Neben den einzelnen Positionsdaten gibt es auch die Kreditoren-ID, den Rechnungsempfänger, zu belastende Kostenstellen und weitere Informationen.
Um die richtigen Bestellnummern zu finden, wird mithilfe einer dynamischen Textschablone nach dem Muster der Bestellnummer gesucht. Alle Ergebnisse werden zur Datenbank der offenen Bestellnummern geschickt. Bei Treffern werden die der Bestellnummer anhängigen Informationen als gesicherte Information übernommen.
2) Erkennung des Rechnungsempfängers
Wird der Rechnungsempfänger nicht bereits durch vorhergehende Schritte vorgegeben, muss dieser erkannt werden. Es werden Fuzzy-Search-Technologien genutzt, um die Ergebnisse mit den Debitorendaten abzugleichen. Der Eintrag mit der höchsten Übereinstimmung definiert dann den Rechnungsempfänger.
3) Erkennung des Kreditoren
Im nächsten Schritt wird die Kreditoren-ID erkannt, sofern diese nicht bereits vordefiniert wurde. Dazu werden verschiedene Informationen vom Dokument ausgelesen und zur Datenbank geschickt. Die möglichen Kreditoren werden bereits durch den vorgegebenen Rechnungsempfänger vorgefiltert.
Folgende Informationen von der Rechnung werden zur Datenbank geschickt.
- IBAN
- Umsatzsteuer ID
- Steuernummer
- Adressdaten
- Weitere Informationen
Der beste Treffer nach Abgleich der Daten definiert den Kreditoren.
4) Erkennung der Kopfdaten
Sind Rechnungsempfänger und Kreditor bekannt, wird zuerst nach Kreditorenspezifischen, gesicherten Informationen gesucht. Gesicherte Informationen könnten an dieser Stelle durch vorheriges manuelles oder automatisches hinterlegen von Erkennungslogiken bereits vorliegen. Ist dies nicht der Fall, werden alle Metadaten generisch erkannt.
- Rechnungsnummer: Es gibt eine Anzahl von Ankerbegriffen, die eine Rechnungsnummer definieren (z.B. „Rechnungsnummer“, „RE-NR“, „Belegnummer“). Nach diesen wird gesucht und die Information rund um diesen Begriff wird als mögliche Rechnungsnummer gewertet.
- Rechnungsdatum: Es werden alle auf der Rechnung vorliegenden Daten in eine zeitliche Abfolge gebracht. Dabei spielt es keine Rolle, ob das Datum als TT.MM.JJJJ, MM.TT.JJJJ, T.M.JJ oder mit ausgeschriebenen sowie abgekürzten Monatsnamen geschrieben wurde. Die Monatsnamen sind in verschiedenen Sprachen hinterlegt. Das Datum, was dem heutigen Datum entspricht bzw. das jüngste Datum in der Vergangenheit, wird als Rechnungsdatum angenommen.
- Beträge: Es werden alle vorliegenden Beträge in Betragsketten aufgeteilt. Der größte Betrag wird vorerst als Bruttoendbetrag angenommen. Alle weiteren Beträge werden unter Berücksichtigung von Umfeldinformationen mit der gültigen Liste der erlaubten Steuersätze abgeglichen und mathematisch validiert. Im Standard werden bis zu zwei, und konfigurativ bis zu vier unterschiedliche Betragsketten auf einer Rechnung erkannt. Konnten keine Betragsketten gebildet werden, wird der höchste Betrag weiterhin als Bruttoendbetrag angenommen. Kommt es aufgrund von Fehlern in den OCR-Daten oder falscher Addition der Beträge auf der Rechnung zu Unstimmigkeiten, werden fehlende oder korrigierte Beträge angenommen und an die Validierungskomponente weitergegeben.
5) Erkennung der Positionsdaten
Zur Erkennung der Positionsdaten auf einer Rechnung werden bestimmte hinterlegte Begriffe gesucht, die einzelne Spalten einer Tabelle beschreiben. Werden diese gefunden, wird eine fiktive Tabellenstruktur über das gesamte Dokument gelegt. Anhand dieser Struktur können die Positionsdaten generisch erkannt werden. Bei Rechnungen mit Bestellbezug werden die Positionsdaten aus der Datenbank gegen die Informationen aus der gebildeten Tabellenstruktur abgeglichen und validiert. Die Hauptkriterien für die Validierung sind die Materialnummer und der Einzelpreis. Da die in Rechnung gestellte Menge von der ursprünglichen Bestellung abweichen kann, wird diese stets von der Rechnung genommen. Außerdem kann jede Position gegen einen erfolgten Wareneingang gegengecheckt und hier bereits validiert werden.
Weitere Funktionen der automatisierten Rechnungserfassung
Wurden alle relevanten Informationen von einer Rechnung erfasst und ausgelesen, werden diese an die Validierungskomponente geliefert. Hier besteht die Möglichkeit, alle erkannten Daten und Werte durch Mitarbeiter:innen validieren zu lassen.
Dazu werden die ausgelesenen Informationen per Sichtkontrolle mit dem Rechnungsdokument abgeglichen. Stimmen Daten nicht überein, können diese ergänzt bzw. korrigiert werden. Dies geht über Datenbankabfragen oder z.B. per Doppelklick (adhoc OCR) auf der entsprechenden Information auf dem Rechnungsdokument.
Innerhalb des Validierungsclient können darüber hinaus sowohl eine §14 Vorprüfung als auch eine Dublettenprüfung automatisiert vorgenommen werden. Bei der §14 Prüfung werden alle relevanten und gegen die Datenbank abgeglichenen Informationen mit den gemäß §14 nötigen Informationen abgeglichen. Die Dublettenprüfung vergleicht die Rechnungsnummer und die Kreditoren-ID gegen historische Daten bereits validierter Rechnungen. Gibt es einen Treffer, besteht die Möglichkeit, dass diese Rechnung bereits verarbeitet wurde.
Weiterhin kann die Validierung auch automatisch im Hintergrund erfolgen. Hierzu können Regeln definiert werden, die bestimmen, wann eine Rechnung den Validierunsgclient überspringen kann. Endanwender:innen der Rechnungsverarbeitungssoftware sehen die Rechnung dann zum ersten Mal im Freigabeworkflow.
Statistiken und Unterstützung der Anwender:innen durch Künstliche Intelligenz (KI)
Jede validierte Rechnung wird mit allen ihren Metadaten temporär in einer Datenbank abgespeichert. Es werden sowohl die ursprünglichen als auch die korrigierten Daten hinterlegt. Somit ist die Qualität der Auslesung jederzeit transparent. Außerdem kann die Statistik genutzt werden, um größere Unstimmigkeiten proaktiv zu beheben. Dazu werden die Stammdaten analysiert und auf fehlende und unstimmige Daten überprüft.
Wurde die Rechnung komplett validiert und an den nachgelagerten Prozess übergeben, tritt außerdem ein KI-basierter Autotrainer in Aktion. Der Autotrainer vergleicht eigenständig die Metadaten vor und nach dem Validierungsclient. Findet er Abweichungen bei z.B. der Rechnungsnummer, wird eine kreditorenspezifische Regel angelegt. Dazu wird sowohl die korrigierte als auch historische Rechnungen dieses spezifischen Kreditors genutzt, um hier die größtmögliche Übereinstimmung zu finden. Auf diese Weise wird die Rechnungsverarbeitungssoftware mit der Zeit selbstständig immer intelligenter und die Erkennungsquoten bei zukünftigen Rechnungen des Kreditors stetig optimiert.
Welche weiteren Vorteile eine KI-basierte und automatisierte Rechnungsverarbeitung bietet und wie diese in der Praxis aussehen kann, erfährst Du im Webinar.
5 Vorteile einer KI-basierten und automatisierten Rechnungsverarbeitung