
Wie können Computer eigentlich Texte auslesen? Handschrifterkennung macht es möglich! Es geht darum, dass Maschinen sowohl maschinengedruckten als auch handgeschriebenen Text erkennen und verstehen können. In diesem Blogartikel gehen wir auf die Unterschiede zwischen maschinengedrucktem und handgeschriebenem Text ein und erklären, was Handschrifterkennung genau ist. Außerdem zeigen wir dir anhand einiger spannender Praxisbeispiele, wie diese Technologie in unserem Alltag eingesetzt wird.
Maschinengedruckter vs. handgeschriebener Text
Bestimmt ist dir die Erkennung von maschinengedrucktem sowie handgeschriebenem Text schon das ein oder andere Mal begegnet. Nehmen wir den Kontext „Online-Banking“. Die Rechnung der Autowerkstatt wird maschinell erstellt, ausgedruckt und per Post an dich versendet. In deiner Banking-App machst du ein Foto der Rechnung. Die Daten wie Empfänger, IBAN, Verwendungszweck und Betrag werden automatisch extrahiert und für dich vorausgefüllt. Das macht die OCR-Methode – sie liest maschinell erstellten Text aus.
Bleiben wir im Banking Szenario für ein weiteres Alltagsbeispiel. Du erhältst ein ausgedrucktes Formular, um ein SEPA-Lastschriftmandat zu genehmigen. Du füllst das Formular handschriftlich aus. Jetzt wird das Formular gescannt und deine Daten wie die Kontonummer werden maschinell ausgelesen und im System hinterlegt. Für diese Handschrifterkennung ist die Methode der HWR oder auch Handwriting Recognition zuständig.
Handschrift erkennen – Praxisbeispiele und Definition
Schauen wir uns zunächst einige weitere Praxisbeispiele für die Erkennung von Handschrift an. Die Beispiele haben gemeinsam, dass es sich um eine Kombination aus maschinellem und handschriftlichem Text handelt.
- Formulare verschiedener Art
- Anmeldebögen beim Arzt oder im Krankenhaus
- Besprechungsnotizen
- Lieferscheine – häufig: handschriftliche Ergänzung der Bestellnummer
- Ausfüllen eines SEPA-Lastschriftmandat
- Bestellformulare oder -tabellen in Katalogen
- Schadensformulare für die Versicherung
- Diverse Belege, um weitere Nummern ergänzt
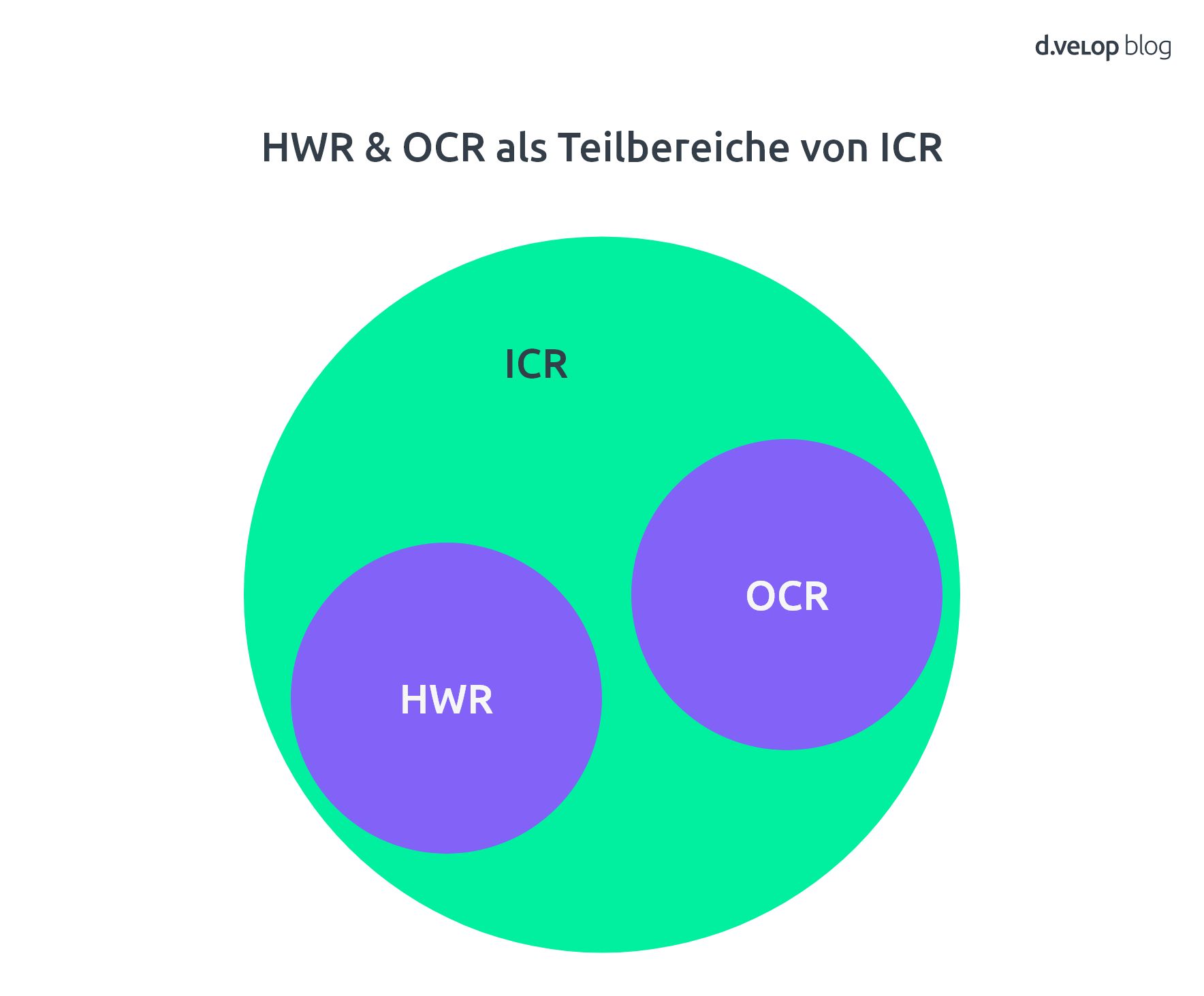
Im Zusammenhang von HWR fällt auch das Kürzel ICR. Dieses steht für Intelligent Character Recognition. Die Differenzierung der beiden Begrifflichkeiten ist nicht ganz einfach, da es Überschneidungen und fließende Übergänge gibt. Allerdings kann man sagen, dass ICR das Lesen über den reinen Textinhalt hinaus bedeutet. Die intelligente Erkennung kann als „Upgrade“ der OCR-Technologie verstanden werden.
Definitionen
Optical Character Recognition (OCR): Die Technologie, um maschinellen Text in Dokumenten zu erkennen. Dadurch wird der Text editier- und durchsuchbar gemacht.
Handschrifterkennung (HWR): Es werden Wörtern, Zeichen und Zahlen erkannt. Dabei wird Handgeschriebenes in maschinenlesbare Zeichen konvertiert.
Intelligent Character Recognition (ICR): Versteht sich als Erweiterung der OCR und HWR. Die Methode dient der Kontextanalyse – beispielsweise „8aum“ oder „Baum“.
Linguistik und Statistik
Die Erkennung von Schriftstücken kann in verschiedene Abstufungen unterteilt werden. Die Texterkennung funktioniert am genauesten bei digitalem, maschinellem Text. Danach folgen gescannte Dokumente mit maschinellem Text. Auch bei der Erkennung von Handschrift gibt es Unterschiede: Gut leserliche Block- bzw. Druckschrift kann genauer ausgelesen werden als unleserliche, fließende Schreibschrift.
Uns Menschen geht es da auch nicht anders. Allerdings besitzt die Technik Mechanismen, um die Erkennung so genau und plausibel wie möglich zu machen. Ein wichtiger Mechanismus sind Wörterbücher. Wörterbücher bieten der Maschine linguistische Trainingsdaten.
Die Qualität der Handschrifterkennung ist auch abhängig von der Sprache. Das Ganze kannst du dir so vorstellen: Zu einer Sprache, die weitverbreitet ist wie Deutsch, Englisch oder Spanisch gibt es üblicherweise eine Menge Trainingsdaten. Sprachen, die kaum verbreitet sind, bieten tendenziell weniger Trainingsdaten an. Kleiner Funfact: Die Sprache „Yuchi“ ist die weltweit seltenste Sprache. Angeblich gibt es nur noch 5 Menschen, welche die Sprache der amerikanischen Ureinwohner überhaupt noch sprechen.
Der eigentlichen Erkennung nachgelagert findet ein Validierungsschritt statt. Klassische Fehlzuordnungen kennen wir alle: I, l und |. Von links nach rechts: ein großes I, ein kleines L und ein Pipe Zeichen. Oder die Verwechselung von der Zahl 0 mit dem Buchstaben O – auch ein Klassiker. Das Einspeisen verschiedener Regeln und statistischer Annahmen minimiert solche Verwechselungen.
Handschrifterkennung im d.velop document reader
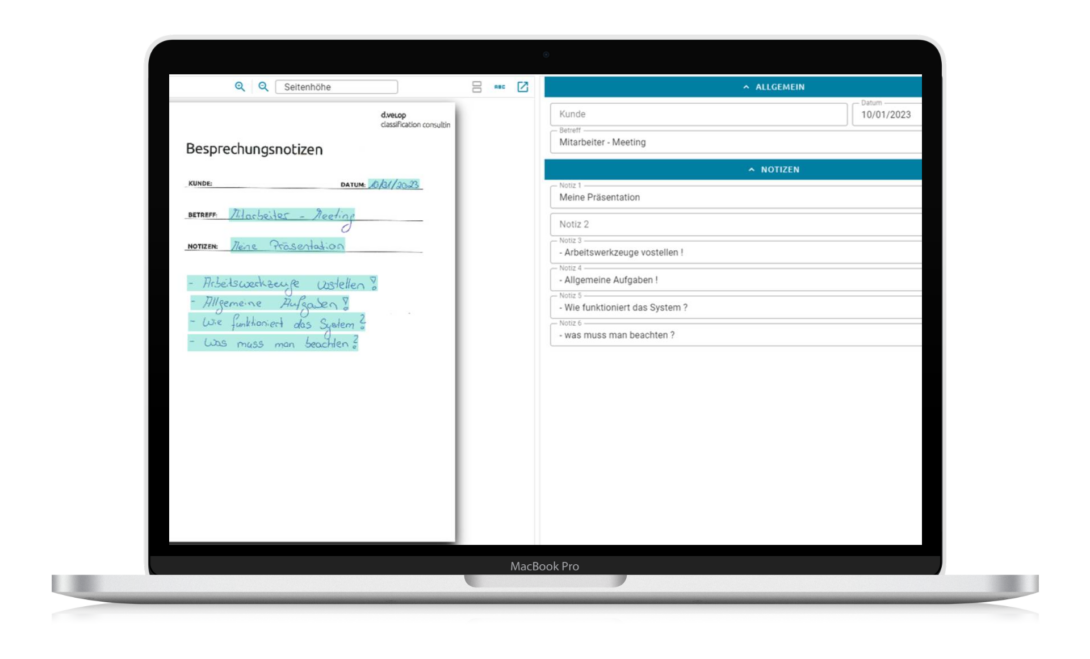
Der nachfolgende Screenshot zeigt einen Auszug aus dem d.velop document reader. Auf der linken Seite sind die erkannten Besprechungsnotizen blau markiert. Auf der rechten Seite sind sie strukturiert und in eine maschinengenerierte Schrift übersetzt.
Tipps zum Aufbau eines Formulars
Die Banken machen es vor, mit ihren Überweisungsträgern. Pro Kästchen bitte nur einen Druckbuchstaben oder eine Zahl. Aber auch bei anderen Formularen kannst du ein paar Sachen beachten, um das Erkennen der Handschrift möglichst genau zu machen:
- Große Felder: Wer kennt es nicht – ist das Feld zu klein, wird gequetscht oder eine neue Zeile eröffnet und die handgeschriebenen Wörter überlappen sich und sind nur schwer zu entziffern. Also – die Felder mit entsprechender Größe planen.
- Hilfslinien: Nicht umsonst heißt sie „Hilfs“-linie. Denn die oft feine Markierung zeigt an, wo der Text platziert werden soll. Buchstaben wie q, p, g, j, y werden von manchen Kalligrafie-Künstlern gern mal ein wenig überschwänglich gemalt. Was passiert? Der Bogen rutscht außerhalb des Feldes, was die Erkennung beeinträchtigen kann.
- Hinweise zur Sensibilisierung: Lass die Leute wissen, dass dein Formular maschinell ausgelesen wird. Formuliere eine Bitte leserlich und in Druckbuchstaben zu schreiben.