Tracing ermöglicht es, verteilte Systeme effektiv zu überwachen und zu analysieren, um Einblicke in deren Leistung und Verhalten zu gewinnen. Real User Monitoring (RUM) ergänzt dies, indem es Leistung und Verhalten von Apps aus der Perspektive tatsächlicher Benutzer:innen überwacht. Besonders hilfreich sind dabei die Web Vital Metriken, die Entwickler:innen wertvolle Daten liefern, um die User-Experience in Bezug auf Ladezeit, Interaktivität und visuelle Stabilität zu verbessern.
Proof-of-Concept: Integration von Telemetrie in die d.velop platform
Ein Proof-of-Concept mit den drei d.velop platform Bausteinen ShellApp, AppRouter und BusinessObjects zeigt, wie Produkt-Teams von diesen Daten profitieren können. Gleichzeitig belegt das Konzept, wie einfach und zentral sich Telemetrie in eine bestehende Software-Landschaft integrieren lässt. Damit das volle Potenzial dieser Ansätze ausgeschöpft wird, sollten alle relevanten Bausteine einer solchen Software-Landschaft den W3C Trace Context und Tracing implementieren.
Grundlagen auf dem Weg zur datengetriebenen Produktentwicklung
Auf dem Weg zur datengetriebenen Produktentwicklung sind jedoch einige grundlegende Aspekte zu berücksichtigen. Datenschutz- und Sicherheitsfragen müssen sorgfältig geprüft, Datenmengen und Performance-Auswirkungen abgeschätzt werden. Ebenso ist eine klare Abwägung notwendig, welche Daten aus kontrollierten Laborumgebungen und welche aus realen Nutzungsszenarien analysiert werden sollen.
Motivation: Ein „Telemetrie-Buffet“ für umfassende Analysen
„Warum nur einen Datentopf anrühren, wenn man gleich ein ganzes Telemetrie-Buffet servieren kann?“ – Genau das dachten wir uns, als wir uns im Rahmen eines teaminternen Hackathons mit dem Thema Nutzungsdatenerfassung auf Frontend- und Backend-Kommunikations-Ebene beschäftigt haben. Unser Ziel war es, ein besseres Verständnis für die Möglichkeiten der Telemetrie-Datenerfassung zu gewinnen und die Daten für umfassendere Analysen verfügbar zu machen. Hierzu wollten wir mit Hilfe von OpenTelemetry (OTel) und Grafana Faro Telemetrie-Daten aus unterschiedlichen Komponenten nach Grafana Cloud übertragen, um die einzelnen Telemetrie-Datentöpfe dort zusammenzuführen und zu verknüpfen. Welche spannenden Erkenntnisse wir dabei gewonnen haben, erfahrt ihr im Folgenden.
Übersicht: Architektur, Tracing und Real User Monitoring
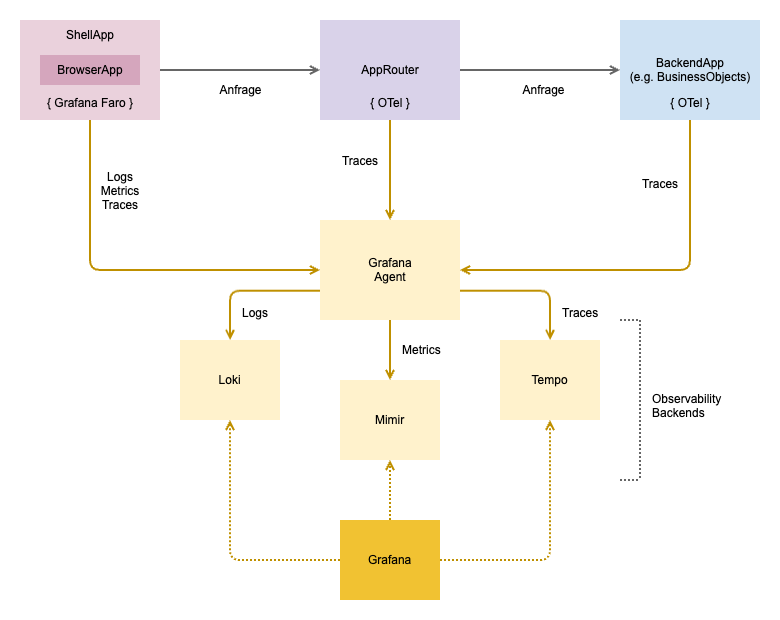
Für unsere prototypische Umsetzung haben wir die Instrumentierung in die ShellApp, den AppRouter und die BusinessObjects integriert.
- Die ShellApp bildet die grundlegende Hülle für alle Apps. Sie stellt den Rahmen für die übergreifende Anzeige, Navigation und Interaktion bereit, in den sich sämtliche Frontend-Apps nahtlos integrieren lassen.
- Der AppRouter fungiert als Reverse Proxy für alle Apps. Er dient als zentraler Einstiegspunkt der d.velop platform und leitet Anfragen basierend auf Routing-Informationen (z. B. URL-Struktur oder Tenant-Informationen) an die zuständigen Apps weiter.
- Die App BusinessObjects stellt zentrale Geschäftsobjekte, wie z. B. Stammdaten, anderen Apps zur Verfügung und erleichtert so die Wiederverwendung und Konsistenz von Daten innerhalb der Plattform.
Diese drei Komponenten senden ihre Telemetrie-Daten (Logs, Metrics, Traces) an eine Grafana Agent genannte Komponente, die sie wiederum an spezialisierte Observability-Backends weiterleitet, namentlich Grafana Loki für Logs, Grafana Mimir für Metriken und Grafana Tempo für Traces. Der Grafana Agent übernimmt dabei die Rolle eines Telemetrie-Kollektors, der für eine effiziente und flexible Datensammlung und -weiterleitung sorgt. Mit Grafana selbst können die Daten dann abgefragt, visualisiert oder z.B. für Alerting-Zwecke genutzt werden. Das Zusammenspiel ist in der folgenden Abbildung skizziert.
Was ist genau ein Trace?
Traces helfen dabei, ganz allgemein gesprochen, verteilte Systeme zu überwachen und zu analysieren und damit Einblicke in deren Leistung und Verhalten zu gewinnen. Sie ermöglichen es, die Ausführung von Apps über verschiedene Komponenten und Services hinweg zu verfolgen. Dies ist besonders in modernen Software-Systemen wichtig, die aus vielen Apps und Microservices bestehen, die miteinander kommunizieren – also ganz wie auf der d.velop platform.
Aufbau eines Trace: Spans und ihre Bedeutung
Ein Trace (Spur) ist eine Abfolge von Ereignissen, die den Pfad eines Aufrufs (z.B. App-Request) durch verschiedene Services und Komponenten zeigt. Er stellt einen einzelnen Vorgang oder eine Transaktion in einem verteilten System dar, z. B. eine Benutzeranfrage, die mehrere Services durchläuft und gibt einen Überblick über den gesamten Lebenszyklus dieser Anfrage. Oder anders gesagt: Ein Trace zeigt, wie sich eine Anfrage von einem Service zum nächsten in einem verteilten System ausbreitet.
Die grundlegenden Bausteine eines Trace sind seine Spans. Ein Span repräsentiert eine einzelne Arbeitseinheit oder eine bestimmte Operation, die als Teil der Anforderung ausgeführt wird. Jeder Span hat einen Start- und einen Endzeitpunkt und kann weitere Informationen wie Events, Fehler oder Tags enthalten. Ein Span repräsentiert insbesondere die Zeit, die eine Operation in einem Dienst (oft einem Microservice) verbracht hat.
Der W3C Trace Context: Standardisierte Trace-Informationen
In unserem Beispiel schicken ShellApp, AppRouter und Backend/BusinessObjects ihre Spans an das Observability-Backend. Aber wie werden die Spans zu einem Trace zusammengefügt? Hier kommt der W3C Trace Context ins Spiel. Kurz gefasst bietet der W3C Trace Context einen standardisierten Weg für das Übermitteln von Trace-Informationen über Service-Grenzen hinweg.
Die etwas längere Fassung: (im Wesentlichen) definiert der W3C Trace Context ein einheitliches Format für Trace-Header, die in HTTP-Anfragen eingefügt werden. Wichtig ist hier vor allem der Header traceparent, der die essenziellen Informationen enthält, die benötigt werden, um Spans über verschiedene Systeme und Technologien hinweg miteinander zu verknüpfen: die traceId, die eindeutige Identifikation des gesamten Traces, und die spanId, die Identifikation des aktuellen Span. Dieser Zusammenhang (Datenfluss) der Spans bzw. Traces ist in der nachfolgenden Abbildung herausgestellt.
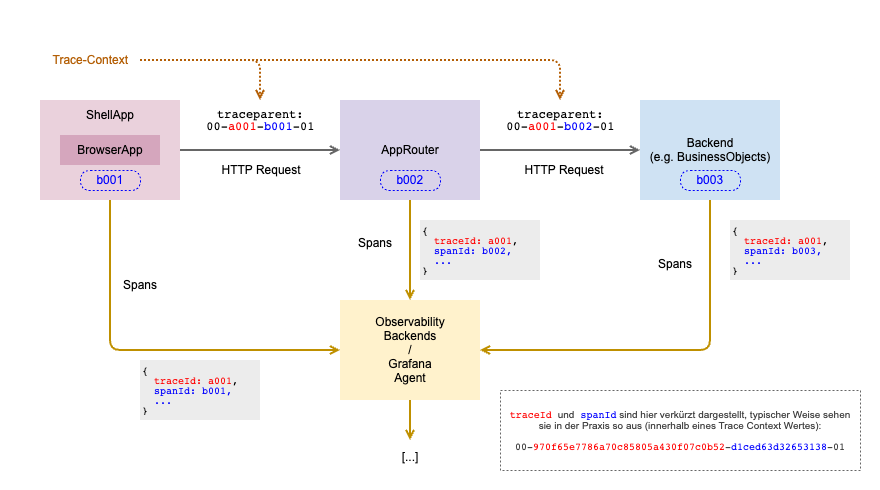
Neben den dargestellten Apps bzw. Services können sich auch andere Infrastruktur-Services in die Trace-Kette „einklinken“ und so können z.B. auch Datenbank-Aufrufe in einem Trace als Span dargestellt werden (wie wir weiter unten sowohl theoretisch als auch praktisch sehen werden).
Und wie sieht ein Trace dann schlussendlich aus?
Die Visualisierung von Traces erfolgt typischerweise in Form eines Gantt-Diagramms, das eine zeitliche Abfolge der Spans zeigt. Dies ermöglicht es, die Performance einzelner Operationen und die Beziehungen zwischen ihnen auf einen Blick zu verstehen. Die Spans werden entlang einer Zeitachse dargestellt, wobei die Länge jedes Spans seiner Dauer entspricht. Dies zeigt auf einen Blick, welche Teile der Anfrage wie viel Zeit in Anspruch genommen haben. Spans, die aus anderen Spans resultieren (z.B. ein Datenbankaufruf, der von einem Service-Request ausgelöst wird), werden hierarchisch unter ihrem übergeordneten Span angezeigt. Dies hilft, die Struktur der Anfrage und die Abhängigkeiten zwischen verschiedenen Operationen zu verstehen. Oft werden Spans zudem unterschiedlich farbig markiert, um beispielsweise ihren Typ (z.B. Datenbankabfrage, externer Service-Aufruf) zu kennzeichnen. Dies erleichtert die schnelle Identifizierung von gleichgearteten und unterschiedlichen Spans.
Beispiel: Trace einer Anforderung
Das nachstehende Diagramm veranschaulicht einen Trace einer Anforderung, die mit einer Benutzerinteraktion innerhalb der ShellApp beginnt und bis zu einem resultierenden Aufruf in der Datenbank nachvollziehbar gemacht wird.
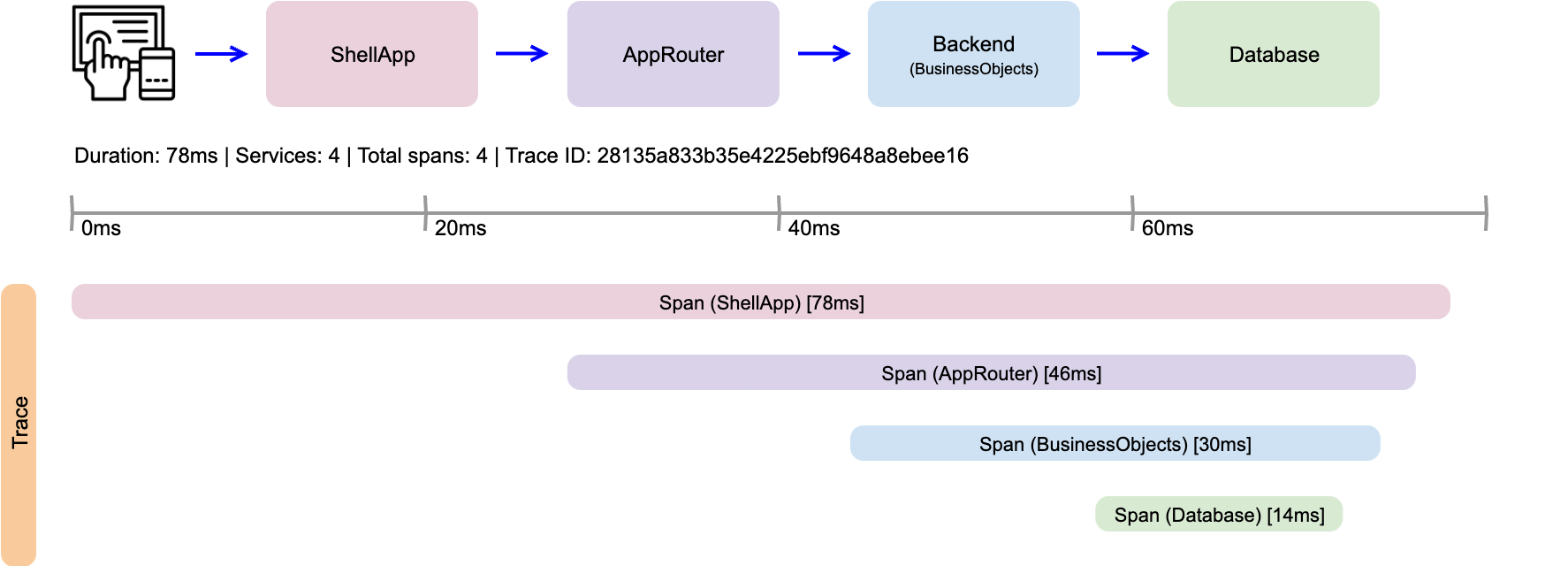
Der Anschaulichkeit halber ist das Beispiel auf eine einfache, sequentielle Eltern-Kind-Beziehung von Spans beschränkt. In der Praxis sind deutlich komplexere, teilweise parallele Beziehungen üblich. Neben den dargestellten Basis-Informationen können nahezu beliebig strukturierte Meta-Informationen an die Spans gehängt werden, z.B. eine vorliegende Tenant-Id. OTel selbst bietet mit den Trace Semantic Conventions eine standardisierte Menge von Regeln und Best Practices für das Tagging und Strukturieren von Traces. Diese Konventionen decken typische Anwendungsbereiche ab, wie etwa Tracing im Bereich HTTP- oder Datenbank-Abfragen.
Real User Monitoring mit Faro: Einblicke in die Benutzererfahrung
Wir sind zunächst mit dem Ziel gestartet, Traces und sogenannte Custom-Events aus einer Browser-App erfassen zu können. Faro bietet jedoch weit mehr, da es sich auf Real-User-Monitoring (RUM) spezialisiert. RUM ermöglicht es, Leistung und Verhalten von Apps und Websites aus der Perspektive der tatsächlichen Benutzer zu überwachen und zu analysieren – daher der Name. Dabei werden Daten in Echtzeit gesammelt, die Einblicke in die Benutzererfahrung geben. Dazu gehören unter anderem Ladezeiten von Apps, Klick-Verhalten, Fehlermeldungen und weitere Interaktionen, die die reale Nutzung und das Verhalten der Endbenutzer widerspiegeln.
Dadurch, dass RUM Daten von tatsächlichen Benutzern sammelt, sind die erfassten Informationen repräsentativ für die Benutzerbasis. Hier liegt der wesentliche Unterschied zu synthetischen Tests. Diese gehen von vordefinierten, künstlich erdachten Szenarien aus, welche in kontrollierten Umgebungen durchgeführt werden. Sie können daher nur eine begrenzte Anzahl von Szenarien abdecken, während die durch RUM gesammelten Daten das Verhalten und die Erfahrungen einer diversen und dynamischen Benutzerbasis unter realen Bedingungen reflektieren. RUM kann daher auch bei der Identifizierung und Behebung von Problemen auf der letzten Meile sehr hilfreich sein.
Auch wenn von tatsächlichen Benutzern die Rede ist, werden die eigentliche Identität oder die persönlichen Daten eines Benutzers für das Real-User-Monitoring nicht benötigt. Die erfassten Daten beziehen sich (im Standard) auf eine generisch gewürfelte Sitzung, die auch nichts mit anderen Sitzungen (z.B. Login-Sitzung) zu tun hat. Die Privatsphäre der Nutzer bleibt bzw. kann vollständig gewahrt bleiben.
Es gibt aber sehr wohl Zusammenhänge zur Produkt-Analyse und zu Business KPIs: so kann RUM beispielsweise dazu beitragen, die Auswirkungen von Leistungsproblemen auf geschäftliche KPIs wie Konversionsraten, Umsatz und Kundenzufriedenheit besser zu verstehen. Auch können RUM-Daten dazu beitragen, den Erfolg von Marketingkampagnen zu messen, indem sie Einblicke in das Engagement der Nutzer und z.B. die Effektivität von Landing Pages bieten.
Rubber on the road
Aber genug der grauen Theorie, bringen wir etwas Gummi auf die Straße und schauen uns an, welchen Nutzen wir überhaupt daraus ziehen können. Den Anfang macht hier Faro. Faro stützt sich intensiv auf die OpenTelemetry-JS-Bibliotheken, um mehrere spezialisierte Instrumentierungen anzubieten, die für das Sammeln und Messen von Daten über die Leistung und das Verhalten von Apps unerlässlich sind:
- Console: Klinkt sich in die Browser-Konsole ein, um Log-Events zu sammeln
- Errors: Erfasst im Browser auftretende (unbehandelte) Fehler
- Tracing: Erfasst detailliert, was passiert, wenn ein Benutzer mit der Browser-App interagiert (insbesondere Kontrollfluss und Datenverlauf)
- Session (Tracking): Erfasst Daten zum Lebenszyklus von Nutzersitzungen (insbesondere deren Start, Fortsetzung, Verlängerung)
- View (Tracking): Ermöglicht das Tracking des Wechsels von Views
- WebVitals: Misst die tatsächliche Leistung in Bezug auf das Nutzungserlebnis
Jede dieser Instrumentierungen sammelt spezifische Daten, die dann einheitlich an den Kollektor, d.h. den Grafana Agent (siehe oben), weitergeleitet werden. Mit Ausnahme der Tracing-Instrumentierung, die bereits in der Grundkonfiguration eine beträchtliche Menge an Daten produziert, sind alle Instrumentierungen standardmäßig aktiviert, sobald Faro im Code (JavaScript oder TypeScript) initialisiert wurde (ein einfacher Funktionsaufruf mit einer Handvoll Parametern). Sie können aber auch jeweils einzeln aktiviert und konfiguriert werden.
Wir haben uns alle genannten Instrumentierungen einmal angeschaut und die Namen bzw. Kurzbeschreibungen sollten einen ersten kurzen Einblick geben können, was sich hinter der jeweiligen Instrumentierung verbirgt. Gleichzeitig erklärungsbedürftig und (aus unserer Sicht) mit unmittelbarem Nutzen verbunden ist aber vor allem die Web Vitals Instrumentierung, die wir nachfolgend etwas detaillierter betrachten.
Web Vitals – Wie nutzerfreundlich sind unsere UIs mit Blick auf Ladezeiten, Interaktivität und visuelle Stabilität?
Bei den Web Vitals handelt es sich um eine Reihe von Metriken, die von Google entwickelt wurden, um Entwicklern zu helfen, die Qualität ihrer Web-Seiten und Web-Apps zu messen und zu verbessern. Sie fokussieren drei Hauptaspekte der User-Experience: Ladezeit, Interaktivität und visuelle Stabilität.
Mit Faro können verschiedene Web Vitals Out-of-the-box gemessen und zentral zur Analyse bereitgestellt werden. Einerseits die Core Web Vitals, die laut Google universelle Aussagekraft für eine gute Web-Experience haben:
- Largest contentful paint (LCP): Misst die Ladeleistung – Zeit, bis der Hauptinhalt der Seite angezeigt wird
- Cumulative layout shift (CLS): Misst die visuelle Stabilität – Quantifiziert, wie oft Nutzer unerwartete Layout-Verschiebungen erleben
- First input delay (FID): Misst die Interaktivität – Zeit zwischen der ersten Interaktion eines Nutzers mit einer Seite und dem Zeitpunkt, zu dem der Browser mit der Verarbeitung von Event-Handlern beginnt
- Interaction to next paint (INP): Beobachtet die Latenz aller Interaktionen durch den Nutzer (Anmerkung: ersetzt zukünftig die FID-Metrik in den Core Web Vitals)
Und anderseits weitere Leistungsmetriken, die eine technischere Leistungsmessung abdecken und spezifischere Fragen beantworten können:
- Time to first byte (TTFB): Die Zeit zwischen dem erstmaligen Abfragen einer Ressource und dem Erhalten des ersten Bytes der Antwort
- First contentful paint (FCP): Zeit, bis der Nutzer erstmalig etwas auf der Seite sehen kann
Hinter den Links sind empfohlene Wertebereiche für die verschiedenen Metriken angegeben. Beispielsweise sollte für eine optimale Web-Experience die ‚Interaction to Next Paint‘ (INP) Zeit 200 Millisekunden oder weniger betragen (im 75%-Perzentil).
Implementierung
Bei der Umsetzung standen wir vor der Frage, wie wir Telemetrie-Daten, einschließlich der hier diskutierten Web Vital Metriken, erfassen können, ohne den einzelnen Entwicklungsteams zusätzlichen Aufwand aufzuerlegen. Wir haben daher Faro in unsere Rahmenanwendung (ShellApp) integriert, so dass die Erfassung automatisch für alle Apps funktioniert, welche die ShellApp nutzen.
Die ShellApp iteriert dazu über alle von ihr verwalteten IFrames und initialisiert dort jeweils Faro. Zudem generiert sie eine Session-Id, die im Session-Storage abgelegt wird und damit implizit einer Browser-Session entspricht. Diese Session-Id wird gemeinsam von den unterschiedlichen IFrames verwendet und stellt damit sicher, dass die Web Vital Metriken (aber auch weitere Telemetrie-Daten) aus den einzelnen IFrames logisch in einer zusammengehörigen Session geklammert werden. Ohne diesen Kniff würde jede Faro-Initialisierung eines jeden IFrames eine eigene Sitzung generieren.
Darüber hinaus extrahiert die ShellApp den Namen der aktiven App aus der aktuellen URL und verwendet diesen als Name sowie den URL-Pfad als Environment für die App-Metadaten, mit der sämtliche Telemetrie-Daten versorgt werden und die z.B. bei analytischen Abfragen in Grafana als Dimension genutzt werden können.
Die nachfolgende Abbildung zeigt einen Screenshot unseres Grafana-Dashboards, das wir im Rahmen unserer Versuchsanordnung mit relevanten Daten befüllt haben. Es veranschaulicht die wesentlichen Web Vital Metriken.
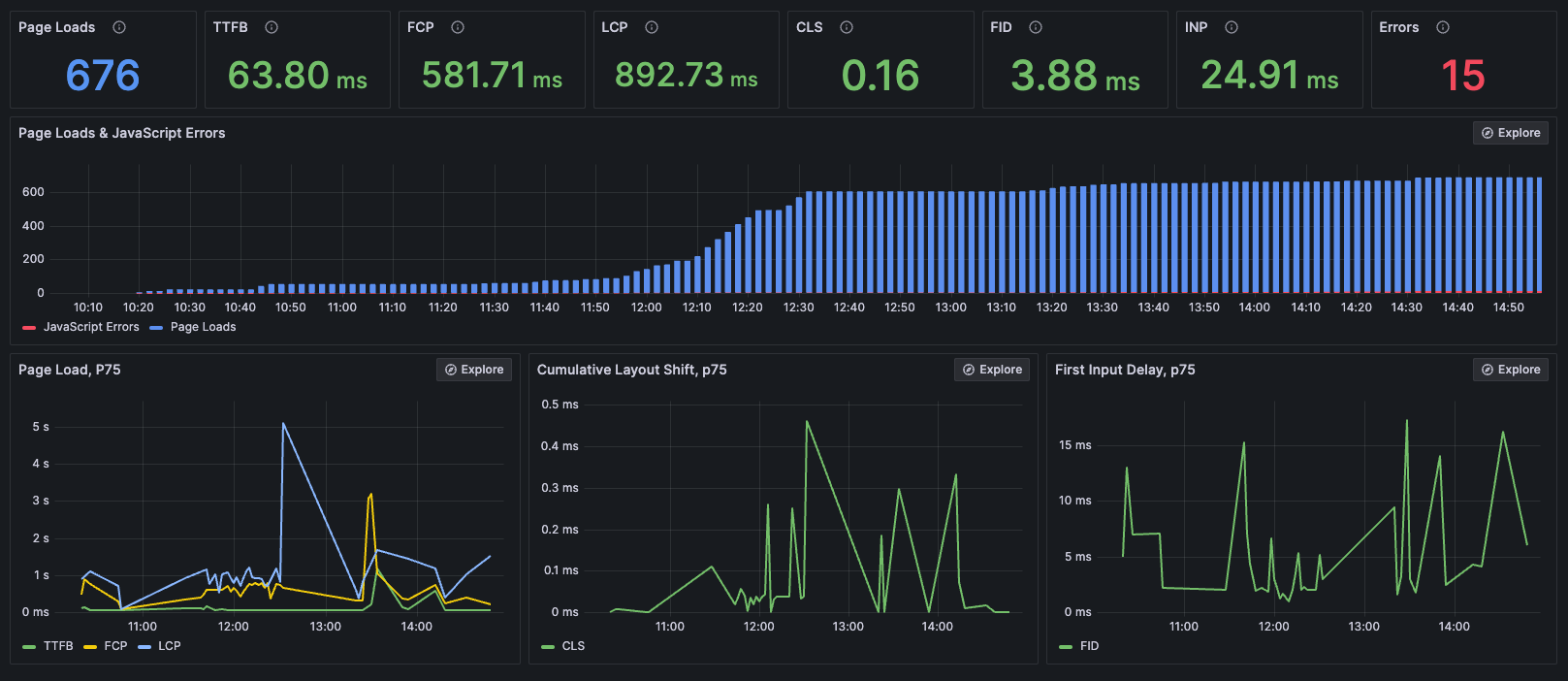
Wie oben erwähnt, werden die Web Vital Metriken mit dem jeweiligen Namen der in der Shell eingebetteten App versorgt. Damit besteht neben der bereits eingebauten Möglichkeit, nach Browser zu filtern, ebenfalls die Möglichkeit, nach Apps zu filtern. Die folgende Abbildung zeigt etwa die Web Vitals für die Dashboard-App im Chrome Browser:
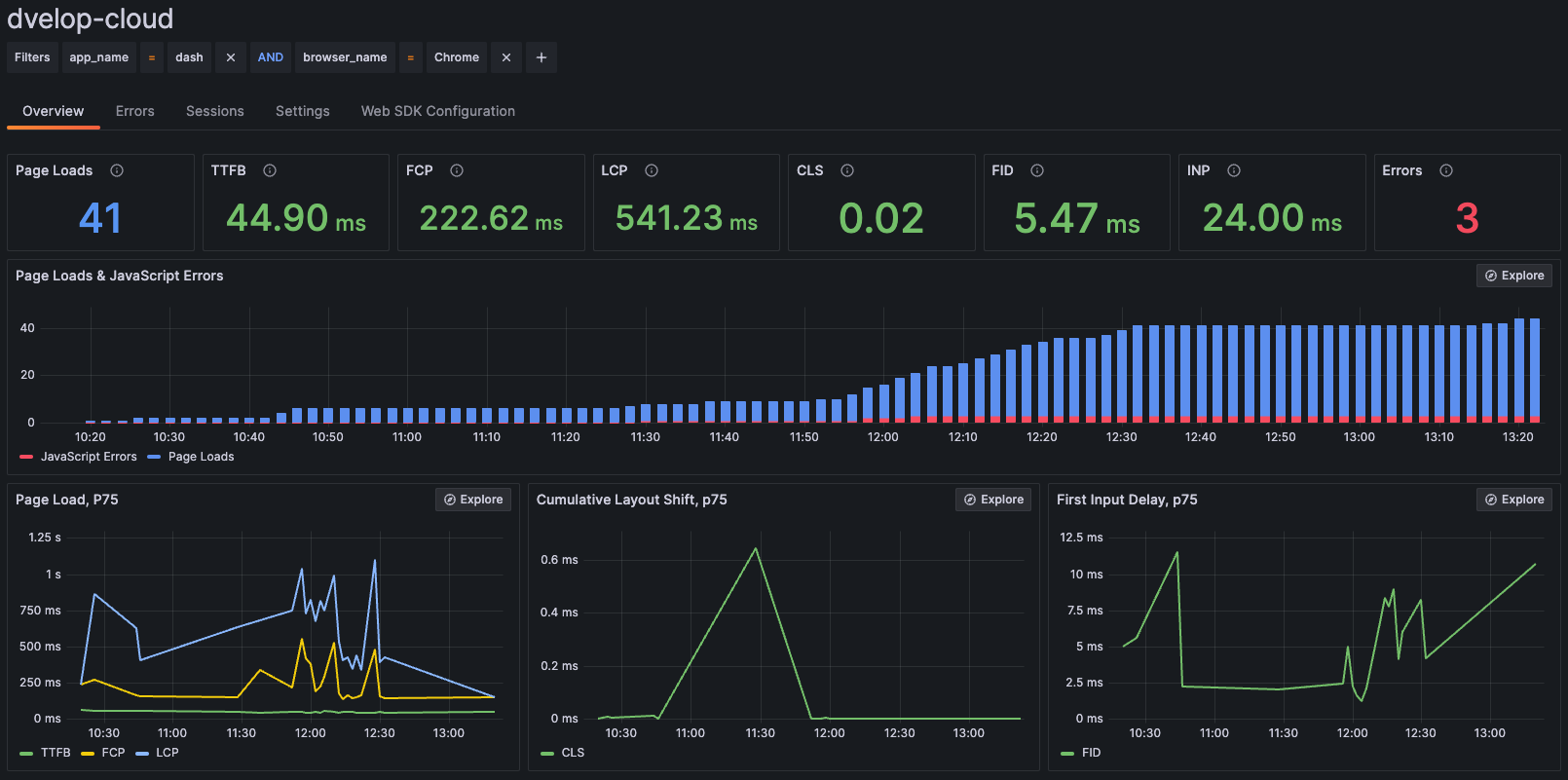
Request Duration – Wo verlieren wir Zeit?
Wie weiter oben bereits angedeutet, sind übergreifende Traces in einer verteilten Architektur nicht nur äußerst hilfreich, sondern mit zunehmender Komplexität und Anzahl von Apps bzw. Services sogar unerlässlich, um kritische Bereiche effektiv zu identifizieren. In diesem Kontext bietet sich der AppRouter, über den sämtliche App-Anfragen innerhalb der Plattform geroutet werden, als idealer Kandidat für die Implementierung von Tracing-Fähigkeiten an. Er verfügt bereits über Zugriff auf eine Vielzahl relevanter Meta-Informationen, wie Tenant-ID, App-Name und HTTP-Attribute, was ihn zu einem idealen Punkt für die Gewinnung wertvoller Tracing-Daten macht.
Beispiel: Tracing-Instrumentierung im AppRouter
Wir haben dazu Tracing mittels OpenTelemetry in den AppRouter integriert. Im Gegensatz zur Auto-Instrumentierung in der ShellApp mit Faro und in BusinessObjects mit OpenTelemetry mussten wir im AppRouter die Spans selbst erzeugen, einen ggf. vorhanden W3C Trace Context von Hand übernehmen/propagieren und letztlich auch die HTTP Basis Attribute selbst am Span setzen.
Beim nachfolgenden Beispiel wurde die Tracing-Instrumentierung zunächst ausschließlich im AppRouter aktiviert bzw. implementiert. Durch die zentrale Rolle des AppRouters ist es aber bereits damit möglich, einen umfassenden Einblick in das Antwortzeit-Verhalten der Plattform-Apps zu erhalten.
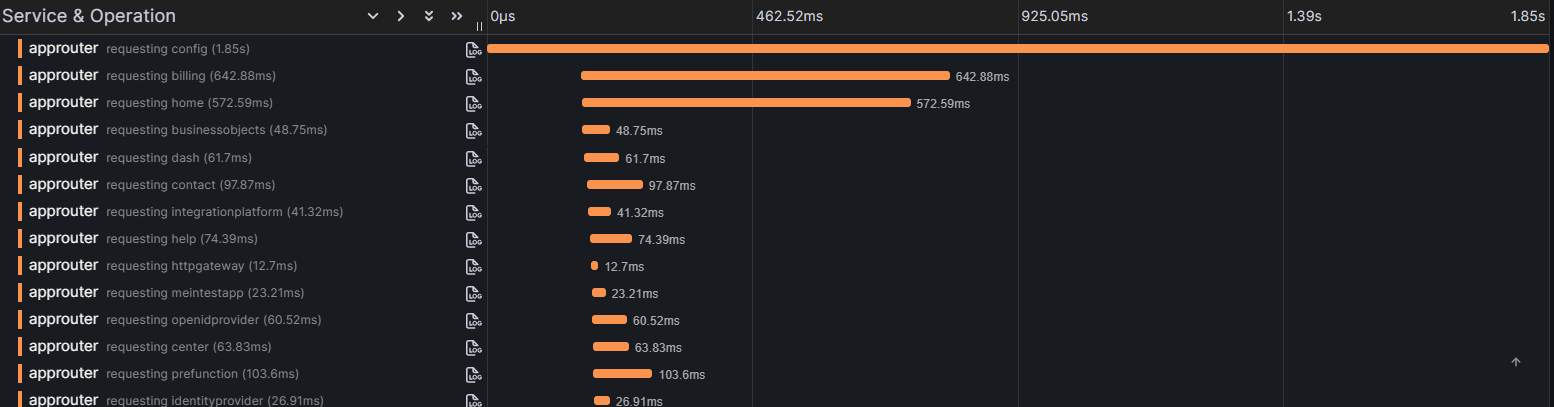
Beispiel: Tracing in BusinessObjects
In der Abbildung ist beispielhaft der Trace eines Aufrufs der ConfigApp zu sehen. Es lässt sich grob ablesen, welche App oder welche Apps primär für die Dauer einer Abfrage verantwortlich sind. Da der AppRouter alle Apps kennt, können die verschiedenen Spans identifiziert und entsprechend benannt werden (‚requesting ‚). Eine noch feinere und exaktere Darstellung können wir erreichen, wenn wir in allen Apps bzw. Services der Plattform OpenTelemetry Traces und den W3C Trace Context implementieren.
Für folgendes Beispiel hat BusinessObjects das getan, d.h. OpenTelemetry Traces aktiviert. Den W3C Trace Context hatte BusinessObjects bereits implementiert. Zusätzlich wurde die client-seitige Tracing-Auto-Instrumentierung für die von BusinessObjects genutzte Datenbank aktiviert. Dadurch ist es möglich, alle Zeiten zwischen einem Klick im Browser bis tief hinab zu den Datenbankabfragen darzustellen und zu analysieren. Die nachfolgende Abbildung veranschaulicht dies beispielhaft anhand eines Traces, der die Erstellung eines Entitätstyps in der Admin-Benutzeroberfläche von BusinessObjects reflektiert.
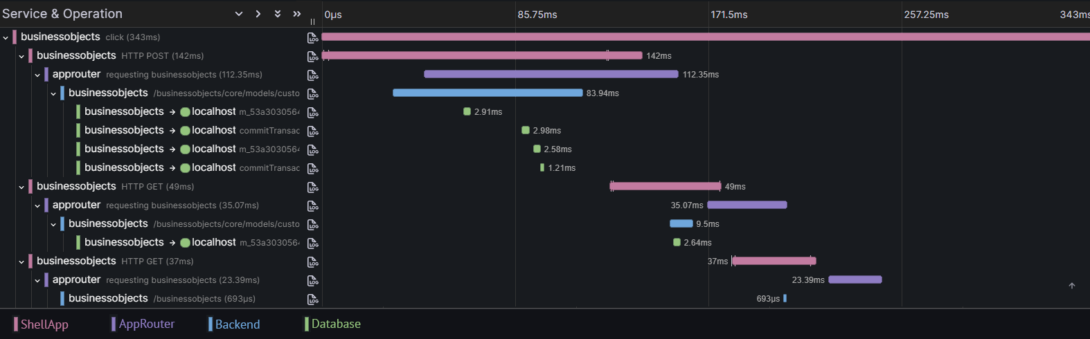
Der oberste Span stammt aus der ShellApp (rosa) und erfasst den ursprünglichen Klick eines Nutzers auf den Speichern-Button. Die Spans auf der zweiten Ebene kommen ebenfalls aus der ShellApp (ebenfalls rosa) und erfassen die drei aus dem Klick resultierenden HTTP Abfragen. Die dritte Ebene kommt aus dem AppRouter (violett), der die drei vorgenannten HTTP Requests zu den passenden Backends routet. In der vierten Ebene sind die Spans aus dem (BusinessObjects-)Backend zu sehen (blau), während die fünfte Ebene die Spans mit den Aufrufen der Datenbank enthält (grün).
An den beiden Screenshots erkennt man, dass noch Arbeit auf uns wartet. Insbesondere müssen wir noch daran arbeiten, dass schneller ersichtlich ist, welcher Span aus welchem Subsystem kommt, etwa durch verbesserte Namenskonventionen oder passende Span-Attribute.
Fazit und Ausblick
Ergebnisse und Erkenntnisse
Anhand unseres Beispiels mit ShellApp, AppRouter und BusinessObjects haben wir aufgezeigt, wie Produkt-Teams von Telemetrie-Daten profitieren können. Durch die Verbindung von browserseitig initiierten Traces mittels Faro in der ShellApp und der Integration von OpenTelemetry im AppRouter entstehen bereits grobgranulare Traces der Software-Landschaft.
Mit einer durchgängigen Implementierung von Tracing (einschließlich W3C Trace Context) könnten vollständige Pfade vom Klick im Browser über den AppRouter, Backends und Datenbanken bis hin zur finalen Anzeige dargestellt und analysiert werden. Die Integration von Real User Monitoring (RUM) ermöglicht zudem wertvolle Einblicke in die tatsächliche Benutzererfahrung. Direkte Feedback-Schleifen aus der realen Nutzungsumgebung helfen, Probleme zu identifizieren, die in synthetischen Testumgebungen möglicherweise nicht sichtbar sind.
Durch die Integration von Faro in die ShellApp können wir für alle Apps der Plattform kritische Leistungsindikatoren wie Ladezeiten von Seiten, Interaktionszeiten und visuelle Stabilität erfassen und analysieren.
Tatsächliche Analysen mit echten bzw. repräsentativen Daten stehen noch aus. Exemplarisch möchten wir die zuvor erörterten Fragestellungen wiederholen, die bisher lediglich als Proof-of-Concept in einer Testumgebung validiert wurden:
- Entsprechen die Web Vitals unserer Apps auch unter realen Bedingungen (im Feld) den Branchenstandards für eine optimale User-Experience?
- In welchen Bereichen der Interaktion oder Kommunikation zwischen Apps treten zeitliche Verzögerungen und Engpässe auf, und welche Optimierungspotenziale ergeben sich daraus?
- Welche Apps und Features werden grundsätzlich wie häufig genutzt, und welche daraus resultierenden Hypothesen sollten im Detail validiert werden?
Aus den bisherigen Überlegungen ergeben sich schnell weiterführende Fragestellungen, die tiefere Einblicke und Optimierungspotenziale bieten:
- Wie lassen sich Nutzeraktionen – insbesondere die von technischen API-Nutzern, die möglicherweise sogar den größten Einfluss haben – über eine gesamte Software-Landschaft hinweg nachvollziehen? Welche Interaktionen finden statt, wo bestehen potenzielle Hürden, und an welchen Stellen ergeben sich Ansatzpunkte für die Optimierung von Abläufen?
- Wie nutzen Benutzer die Plattform, und welche Herausforderungen begegnen ihnen dabei? Welche konkreten Maßnahmen können ergriffen werden, um die User Experience zu verbessern und den Gesamtablauf effizienter zu gestalten?
- Ist es mit den gesammelten Daten möglich, „unerklärliche Anomalien“ in der Plattform-Performance zu identifizieren und zu analysieren? Ein Beispiel könnte die starke Schwankung der System-Performance im Tagesverlauf sein. Welche Ursachen stecken dahinter, und welche Maßnahmen lassen sich daraus ableiten?
Entwickler können ihre Apps mit geringem Aufwand mit Tracing-Instrumentierung versehen, insbesondere dank der Auto-Instrumentierung von OpenTelemetry. Anhand der Beispiele ShellApp und BusinessObjects konnten wir zeigen, dass dies mit nur wenigen Codezeilen möglich ist. Beim AppRouter war ein anderes Vorgehen erforderlich, da hier die Traces und Spans manuell erzeugt werden mussten. Die Magie der OTel-Auto-Instrumentierung beschränkt sich jedoch nicht nur auf Tracing. Sie umfasst auch Metriken, wie wir im Zusammenhang mit Web Vitals durch Faro sowie in anderen Projekten außerhalb dieses Kontexts feststellen konnten.
Empfehlungen
Tracing bietet vielseitige Anwendungsmöglichkeiten, vor allem in den Bereichen Performance-Optimierung, Fehlerdiagnose und -behebung, Skalierung und Skalierbarkeit sowie allgemein im Rahmen der Observability. Es ermöglicht, Engpässe zu identifizieren, Probleme in der Systemarchitektur nachzuvollziehen und Systeme besser auf wachsende Anforderungen auszurichten. Ein besonderer Vorteil von Tracing ist die Möglichkeit, automatisch Metriken – insbesondere RED-Metriken – aus Traces und Spans abzuleiten.
Darüber hinaus kann Tracing auch im Kostenmanagement unterstützen. Es liefert Einblicke in die Nutzung von Systemressourcen und hilft, deren Zuweisung zu optimieren. Gleichzeitig ermöglicht es, Entwicklungsressourcen gezielt zu priorisieren, indem es aufzeigt, welche Bereiche der Plattform am meisten von Optimierungen profitieren würden.
Um das volle Potenzial von Trace-Analysen auszuschöpfen, ist eine durchgängige Implementierung auf der gesamten Plattform notwendig. Alle Apps und Services sollten Tracing und den W3C Trace Context unterstützen, indem sie diesen aufnehmen und weitergeben.
Faro und Real User Monitoring (RUM) sind insbesondere im Zusammenhang mit den Web Vitals vielversprechend. Diese Analysen könnten bereits jetzt größere Erkenntnisse für alle Apps auf der Plattform liefern. Bei anderen RUM-Instrumentierungen müssen Nutzen und Machbarkeit noch genauer bewertet werden, doch auch hier sehen wir schon jetzt Potenzial für weiterführende Analysen und Optimierungen.
Herausforderungen
Bei der Erfassung und Analyse von Telemetrie-Daten ergeben sich einige grundlegende Herausforderungen. Insbesondere muss entschieden werden, welche Daten unter kontrollierten „Laborbedingungen“ in einer simulierten Umgebung (z. B. einer QA-Umgebung) erfasst werden und welche direkt „im Feld“ mit realen Nutzern gemessen und analysiert werden sollen. Diese Abwägung beeinflusst maßgeblich die Aussagekraft und die technische Machbarkeit der Analyse.
Ein zentraler Aspekt ist die schiere Menge an Daten, die dabei generiert werden kann. Diese Datenmengen sollten immer unter Berücksichtigung des Kosten-Nutzen-Verhältnisses verarbeitet werden. Dabei dürfen Kosten nicht nur als finanzieller Aufwand für Datentransfer verstanden werden. Auch die Auswirkungen auf die Systemleistung – insbesondere im Browser – müssen bedacht werden, da Instrumentierungen und der zugehörige Datenverkehr potenzielle Performance-Einbußen mit sich bringen können.
Ein weiteres technisches Detail betrifft die Integration von Telemetrie-Endpunkten, wie sie beispielsweise für Real-User-Monitoring genutzt werden. Solche öffentlichen Endpunkte müssen ausreichend geschützt sein, um Sicherheit und Verfügbarkeit zu gewährleisten, etwa gegen Überlastungsangriffe. Gleichzeitig sollte sich die Nicht-Verfügbarkeit eines solchen Endpunktes nicht auf die Kernfunktionen der betroffenen Anwendungen auswirken.
Nicht zuletzt ist der Datenschutz ein essenzieller Faktor. Alle gesammelten Daten müssen den geltenden gesetzlichen Datenschutzanforderungen entsprechen und verantwortungsvoll behandelt werden. Dies gilt insbesondere bei der Erfassung und Analyse von Daten, die die Interaktionen realer Nutzer betreffen.
Trotz dieser Herausforderungen gibt es effektive Strategien, um diesen Anforderungen gerecht zu werden. Adaptives Sampling kann beispielsweise sicherstellen, dass die Datenmenge repräsentativ bleibt, während der Ressourcenbedarf reduziert wird. Eine maßgeschneiderte Konfiguration ermöglicht es, nur gezielte Instrumentierungen zu aktivieren und irrelevante Daten zu filtern. Zusätzlich können Request-Limiting-Mechanismen eingesetzt werden, um Endpunkte vor Überlastung zu schützen. Mit diesen Ansätzen lassen sich die technischen und organisatorischen Herausforderungen effizient bewältigen, während gleichzeitig wertvolle Einblicke in das Nutzungsverhalten ermöglicht werden.
Was bleibt?
Abschließend lassen sich zwei zentrale Erkenntnisse festhalten:
- Erstens steckt in den Themen Tracing und Real User Monitoring ein enormes Potenzial. Die Fähigkeit, umfassende Telemetrie-Daten zu erfassen und gezielt miteinander zu verknüpfen, liefert wertvolle Einblicke in die Funktionsweise von Systemen und das Verhalten der Nutzer. Der Blick auf einzelne Datensilos reicht dabei nicht aus – es lohnt sich, ein ganzes Telemetrie-Buffet anzubieten, um datenbasierte Entscheidungen zu treffen und die Weiterentwicklung von Anwendungen gezielt voranzutreiben.
- Zweitens ist es entscheidend, im oft hektischen Arbeitsalltag bewusst Freiräume für Forschung und Innovation zu schaffen. Ohne diese kreativen Pausen bleiben viele vielversprechende Ideen und Ansätze ungenutzt. Zeit für Experimente und das berühmte „Out-of-the-Box-Denken“ ist unerlässlich, um neue Technologien zu testen, Prozesse zu optimieren und die eigene Perspektive zu erweitern. Innovation entsteht nicht im Autopilot-Modus, sondern dort, wo Neugier und Gestaltungsfreiraum aufeinandertreffen.
Daten sind ein wesentlicher Schlüssel zur Weiterentwicklung – doch ihr wahres Potenzial entfaltet sich erst, wenn wir bereit sind, sie sinnvoll zu verknüpfen und zielgerichtet zu nutzen. Technologien wie Tracing und Real User Monitoring sind zwei mögliche Bausteine, um Systeme nutzerzentrierter und effizienter zu gestalten. Um das herauszufinden, müssen wir experimentieren! Bleiben wir also neugierig – die besten Ideen entstehen, wenn wir bereit sind, Neues zu wagen.
Dein Job in der Entwicklung bei d.velop
wartet auf Dich!
Entwickeln ist bei uns nicht einfach nur ein Job, sondern eine Leidenschaft. Wir stehen hinter unserem Code, den wir zusammen mit über 200 Personen in unseren agilen, crossfunktionalen Teams in der Entwicklung schaffen.
Co-Autoren:
- Michael Schlottbom I Head of d.velop platform I Senior Product Manager I d.velop AG
- Michael Eing I Software Development Engineer I d.velop AG
- David Gross | Senior Software Development Engineer | d.velop AG